統計估計和誤差範圍#
資料視覺化有時涉及匯總或估計步驟,其中會將多個資料點縮減為摘要統計資料,例如平均值或中位數。當顯示摘要統計資料時,通常適合作為加入誤差範圍,其提供視覺提示,說明此摘要代表基本資料點的程度。
如果提供完整資料集,許多 seaborn 函數將自動計算摘要統計資料和誤差範圍。本章說明如何控制誤差範圍的顯示內容,以及您可能選擇 seaborn 提供之每個選項的原因。
圍繞集中趨勢估計的誤差條可顯示兩項一般資訊:對估計值的確定性範圍或其周圍基本資料的分散。這些度量相關:在相同樣本大小下,當資料分散程度較高時,估計將更不確定。但是,不確定性將隨著樣本大小增加而降低,而分散程度則不會。
在 seaborn 中,建構每個種類的誤差範圍有兩種方法。一種方法是參數化,採用依賴分配形狀假設的公式。另一種方法是非參數化的,僅使用您提供的資料。
您的選擇是用於每個函數作圖時估計的部分的 errorbar 參數所決定。此參數接受要使用的方法名稱,以及控制區間大小的參數(可選擇)。選擇可以定義在二維分類法,其依賴顯示的內容以及如何建構

您會注意到,參數大小對參數和非參數途徑的定義不同。對於參數誤差棒,它是一個乘上定義誤差的統計數字(標準誤差或標準差)的純量因子。對於非參數誤差棒,它是一個百分比寬度。以下會針對每個特定途徑進一步說明。
註
此處描述的 errorbar API 於 seaborn v0.12 推出。在先前的版本中,唯一的選項是顯示 bootstrap 信賴區間或標準差,其選擇是由 ci 參數控制(亦即 ci=<size> 或 ci="sd")。
若要比較不同的參數化,我們將使用下列輔助函數
def plot_errorbars(arg, **kws):
np.random.seed(sum(map(ord, "error_bars")))
x = np.random.normal(0, 1, 100)
f, axs = plt.subplots(2, figsize=(7, 2), sharex=True, layout="tight")
sns.pointplot(x=x, errorbar=arg, **kws, capsize=.3, ax=axs[0])
sns.stripplot(x=x, jitter=.3, ax=axs[1])
資料分散的測量#
代表資料分散的誤差棒,使用三組數字提供分布的精簡顯示,其中 boxplot() 將使用 5 或更多,而 violinplot() 將使用複雜的演算法。
標準差誤差棒#
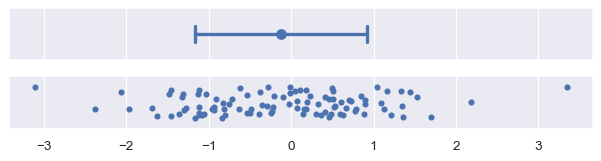
標準差誤差棒是最容易說明的,因為標準差是常見的統計數字。它是每一個資料點到樣本平均值的平均距離。預設 errorbar="sd" 會在估計值周圍的 +/- 1 sd 處繪製誤差棒,但範圍可以透過傳遞縮放大小參數來增加。同時假設資料呈常態分佈,約 68% 的資料將落在一個標準差內,約 95% 將落在兩個標準差內,約 99.7% 將落在三個標準差內
plot_errorbars("sd")
百分比區間誤差棒#
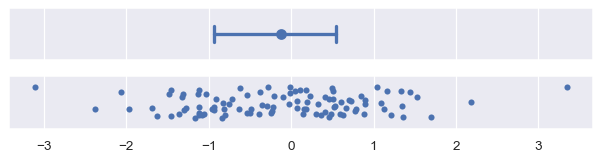
百分比區間也代表部分資料所在的範圍,但它們是直接從您的樣本計算出這些百分比。預設 errorbar="pi" 會顯示從第 2.5 個百分比到第 97.5 個百分比的 95% 區間。您可以透過傳遞大小參數選擇不同的範圍,例如顯示四分位數範圍
plot_errorbars(("pi", 50))
標準差誤差棒永遠會對稱於估計值周圍。當資料呈現偏態時就會形成問題,特別是有自然界限時(例如,若資料代表只能為正數的量)。在某些情況下,標準差誤差棒可能延伸至「不可能」的數值。非參數化方法沒有這個問題,因為它可以計入不對稱的散佈,而且永遠不會超出資料的範圍。
估計值的不確定性測量值#
若你的資料是由較大母體隨機抽出的樣本,則平均值(或其他估計值)將是真實母體平均值的非完美測量值。顯示估計值不確定性的誤差棒試圖顯示真實參數合理數值的範圍。
標準誤差棒#
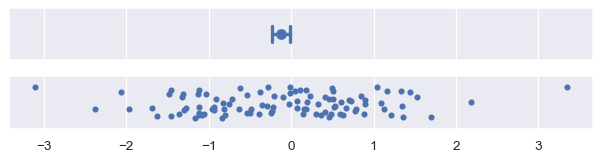
標準誤差統計量與標準差有關:事實上,它就是標準差除以樣本大小的平方根。預設,errorbar="se" 會從平均值繪製區間 +/-1 個標準誤差
plot_errorbars("se")
信心區間誤差棒#
非參數化方法顯示不確定性的作法使用 bootstrapping:一種會以放回的方式隨機重新取樣資料集多次,而且每次會從重新取樣中重新計算估計值的程序。這個程序會建立近似估計值可能獲得的數值分佈(如果你的樣本不同)。
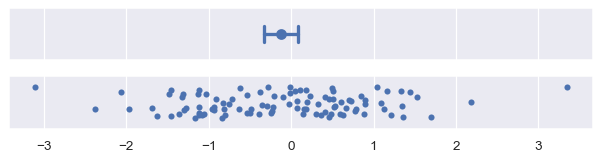
信心區間是透過取 bootstrap 分佈的百分點區間建構的。預設 errorbar="ci" 會繪製 95% 信心區間
plot_errorbars("ci")
Seaborn 的術語有些特別,因為統計資料中的信心區間可以是參數化的,也可以是非參數化的。若要繪製參數化信心區間,請縮放標準誤差,並使用類似於上述內容的公式。例如,近似的 95% 信心區間可以透過取平均值 +/- 兩個標準誤差來建構
plot_errorbars(("se", 2))
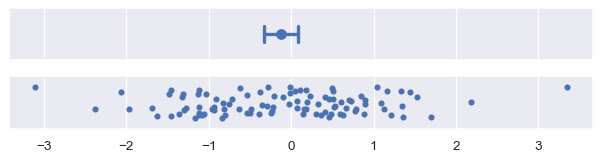
非參數化 bootstrap 有類似百分點區間的優點:它可以自然地適應偏態且有邊界的資料,這是標準誤差區間無法做到的。它也更全面。雖然標準誤差公式特定於平均值,但誤差棒可以使用 bootstrap 來計算任何估計量
plot_errorbars("ci", estimator="median")
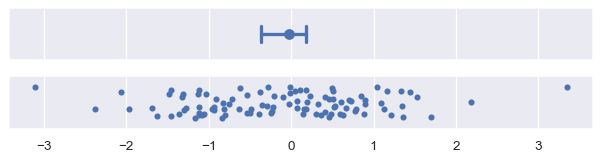
Bootstrapping 涉及隨機性,而且誤差棒每次執行產生它們的程式碼時,顯示的內容都會略有不同。有幾個參數可以控制這個情況。其中一個會設定反覆運算的次數 (n_boot):反覆運算的次數越多,所產生的區間將會越穩定。另一個則是設定亂數產生器的 seed,它將確保結果相同
plot_errorbars("ci", n_boot=5000, seed=10)
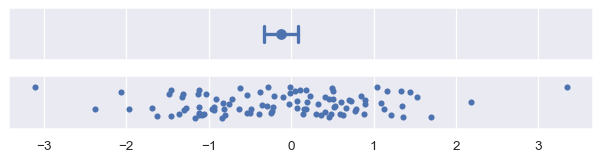
由於它的迭代過程,Bootstrap 區間的運算成本可能很高,尤其針對大型資料集。但是,由於樣本大小會降低不確定性,因此在這種情況下,使用代表資料分散的誤差棒可能是更有用的資訊。
自訂誤差棒#
如果這些範例不符合需求,也可以將一般函式傳遞給 errorbar 參數。此函式應採用向量,並產生一組表示區間最大和最小點的值
plot_errorbars(lambda x: (x.min(), x.max()))
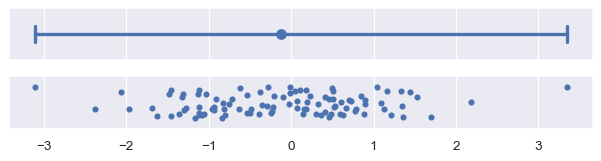
(在實際狀況中,您可以使用 errorbar=("pi", 100) 顯示資料的完整範圍,而不是使用上述的自訂函式)。
請注意,目前 seaborn 函式無法從外部計算的值中繪製誤差棒,但可以搭配 matplotlib 函式將此類誤差棒加入 seaborn 區塊中。
迴歸擬合上的誤差棒#
前述討論著重在參數估計值周圍顯示的誤差棒,這些估計值來自彙整資料。在使用 seaborn 估計迴歸模型以視覺化關係時,也會出現誤差棒。在此情況下,這些誤差棒會在迴歸線周圍顯示一條「範圍」。
x = np.random.normal(0, 1, 50)
y = x * 2 + np.random.normal(0, 2, size=x.size)
sns.regplot(x=x, y=y)
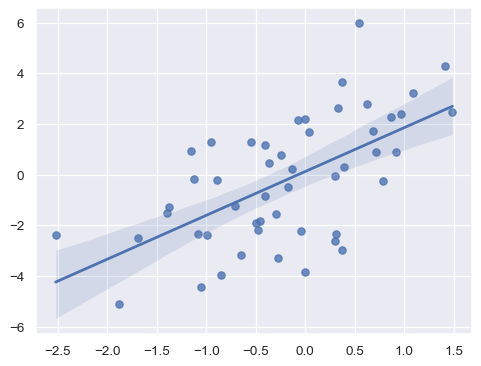
目前,迴歸估計值上的誤差棒較不靈活,只能顯示透過 ci= 設定大小的信賴區間。此部分可能在未來更改。
誤差棒是否足夠?#
您應該總是問問自己是否最好使用只顯示摘要統計資訊和誤差棒的區塊。在許多情況下,並非如此。
如果您有興趣了解摘要的問題(例如群組之間的平均值是否不同或是否隨著時間增加),彙整資料將降低區塊的複雜度並讓這些推論更容易。但是這樣一來,它將模糊底層資料點的寶貴資訊,例如分佈的形狀和異常值的出現。
當分析您自己的資料時,別滿足於摘要統計值。也務必檢視底層分佈。有時,將兩種觀點結合到同一個圖中可能會有所助益。許多 seaborn 函式都可以協助完成這項工作,尤其是 分類教學 中討論的函式。