對 Seaborn 的簡介#
Seaborn 是用於製作 Python 統計圖形的函式庫。它建立在 Matplotlib 之上,並與 Pandas 資料結構緊密整合。
Seaborn 助你探索並了解資料。它的繪圖函數運作於包含完整資料集的資料框和陣列上,並在內部執行必要的語義對應和統計彙總以產生具有訊息的圖形。其以資料集為導向的宣告式 API 讓你著重於圖形中不同元素的意義,而非繪製方法的細節。
下列範例說明 Seaborn 的功能
# Import seaborn
import seaborn as sns
# Apply the default theme
sns.set_theme()
# Load an example dataset
tips = sns.load_dataset("tips")
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
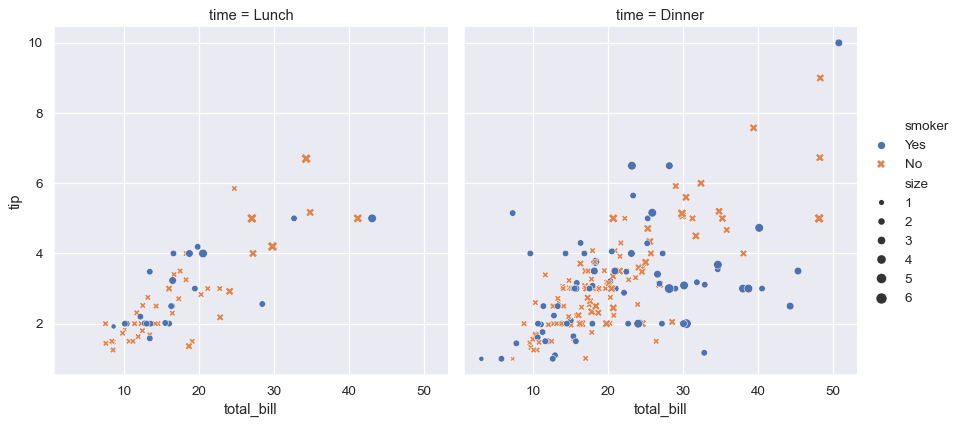
此處發生了幾件事。讓我們一一檢視
# Import seaborn
import seaborn as sns
對於這個簡單的範例,Seaborn 是我們唯一需要匯入的函式庫。按慣例,它會以簡寫方式 sns 匯入。
Seaborn 在幕後使用 Matplotlib 來繪製它的圖形。對於互動的工作,建議使用 Matplotlib 模式 的 Jupyter/IPython 介面,否則,你必須在想要看到圖形時呼叫 matplotlib.pyplot.show()。
# Apply the default theme
sns.set_theme()
這是使用 matplotlib rcParam 系統,它會影響所有 matplotlib 繪圖的外觀,即使您使用 seaborn 建立繪圖也一樣。除了預設主題,還有 幾個其他選項,您可以獨立控制繪圖的樣式和縮放,以在簡報情境之間快速轉換您的工作(例如製作一張在演講時能以可讀字體投影的簡報)。如果您喜歡 matplotlib 的預設值或偏好其他主題,您可以略過此步驟,仍可以運用 seaborn 繪圖功能。
# Load an example dataset
tips = sns.load_dataset("tips")
文件中的大多數程式碼都會使用 load_dataset() 函數快速取得範例資料集。這些資料集並無特別之處,它們只是 pandas 資料框架,而且我們也可以透過 pandas.read_csv() 載入或手動建立。文件中的大多數範例會使用 pandas 資料框架指定資料,但 seaborn 對它接受的 資料結構 有很大的彈性。
# Create a visualization
sns.relplot(
data=tips,
x="total_bill", y="tip", col="time",
hue="smoker", style="smoker", size="size",
)
此繪圖使用單一對 seaborn 函數 relplot() 的呼叫顯示 tips 資料集中五個變數之間的關係。請注意,我們僅提供變數名稱及其在繪圖中的角色。與直接使用 matplotlib 不同的是,不必根據色彩值或標記碼指定繪圖元素的屬性。在幕後,seaborn 處理了資料框架中值到 matplotlib 能理解的引數的轉換。此聲明式手法讓您可以專注於想要回答的問題,而不是控制 matplotlib 的細節。
統計圖表的高階 API#
沒有最好的資料視覺化方式。不同的問題最適合用不同的繪圖回答。Seaborn 讓您可以使用一致的資料導向 API 在不同的視覺表示法之間輕易切換。
函式 relplot() 以這種方式命名,原因在於其設計用於視覺化許多不同的統計關係。雖然散佈圖通常很有效,但當一個變數代表時間量度時,其關係可以用線條更妥善地表示。relplot() 函數有一個實用的 kind 參數,讓您可以輕鬆地切換到這種替代表示法
dots = sns.load_dataset("dots")
sns.relplot(
data=dots, kind="line",
x="time", y="firing_rate", col="align",
hue="choice", size="coherence", style="choice",
facet_kws=dict(sharex=False),
)
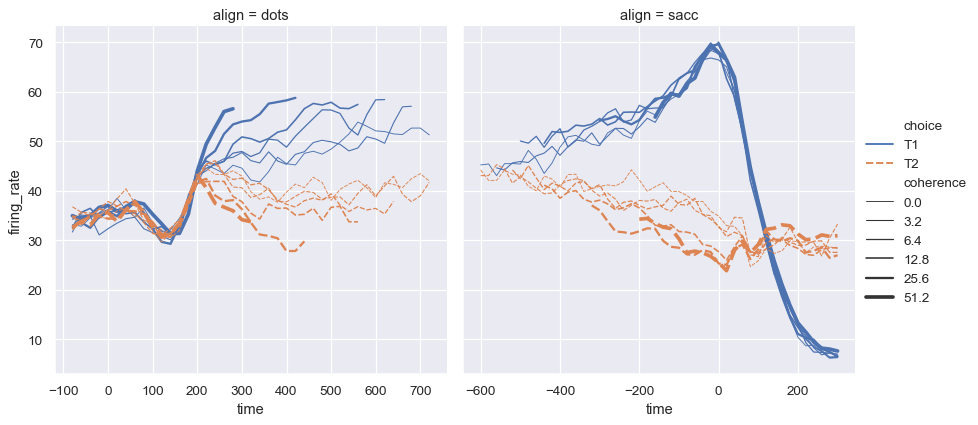
請注意 size 與 style 參數是如何同時用於散佈圖和折線圖中,但它們對兩種視覺化的影響不同:在散佈圖中變更標記區域和符號,而在折線圖中變更線條寬度和虛線。
不需要記住這些細節,這讓我們可以專注於圖表總體結構與我們想要傳達的資訊。
統計估計#
fmri = sns.load_dataset("fmri")
sns.relplot(
data=fmri, kind="line",
x="timepoint", y="signal", col="region",
hue="event", style="event",
)
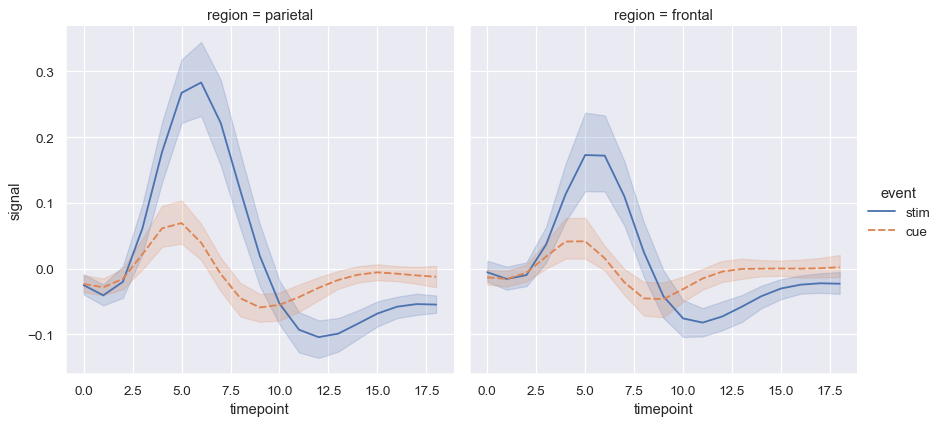
我們通常對一個變數的平均值感興趣,視為其他變數的函數。許多 seaborn 函數會自動執行統計估計,以回答這些問題
當統計值經過估計後,seaborn 會使用開機取樣來計算信賴區間並繪製代表估計不確定性的誤差條形圖。
sns.lmplot(data=tips, x="total_bill", y="tip", col="time", hue="smoker")
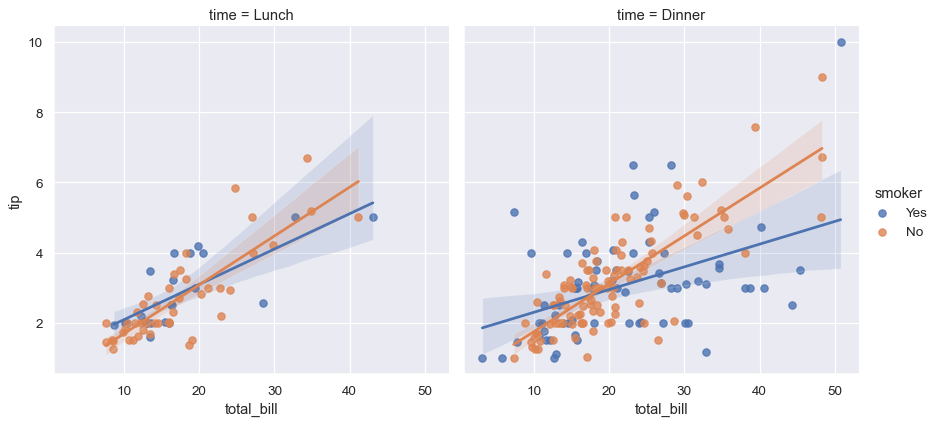
seaborn 中的統計估計超越了描述統計。例如,可以使用 lmplot() 來包含線性迴歸模型(及其不確定性),以增強散佈圖
分佈式表示#
sns.displot(data=tips, x="total_bill", col="time", kde=True)
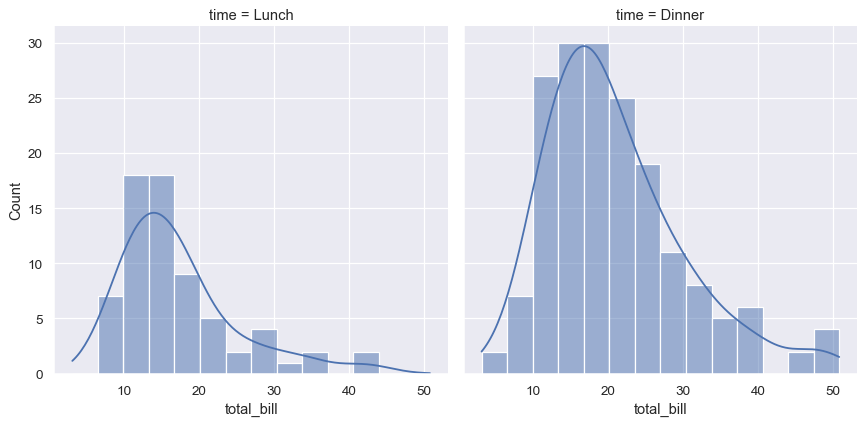
統計分析需要瞭解資料集中的變數分佈。seaborn 函數 displot() 支援數種用於視覺化分佈的方法。它們包括直方圖等傳統技術,以及像核密度估計等運算密集法
sns.displot(data=tips, kind="ecdf", x="total_bill", col="time", hue="smoker", rug=True)
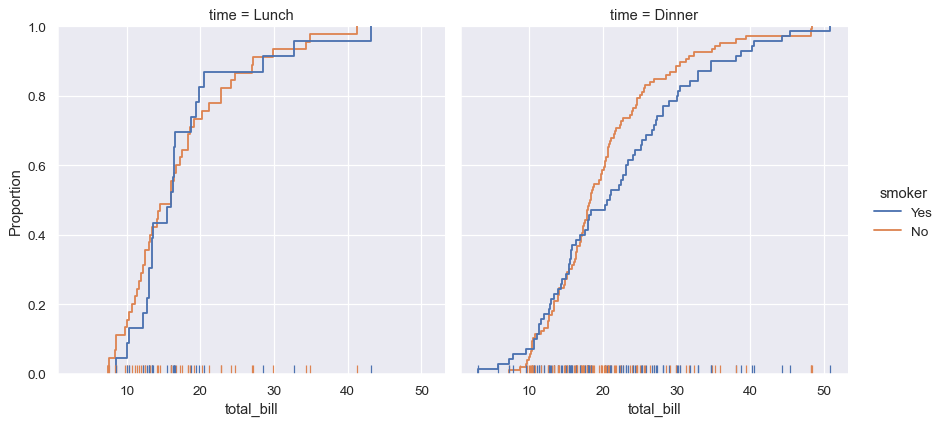
seaborn 也嘗試推廣功能強大但較不熟悉的方法,例如計算和繪製資料的經驗累積分配函數
Seaborn 有好幾種特定繪圖類型是為視覺化分類資料而設計。透過 catplot() 可以存取這些繪圖。這些繪圖提供不同層級的詳細程度。在最精細的層級,你可能會希望透過繪製「蜂群」繪圖來檢視每個觀察值:一個沿著分類軸調整點位置的散佈圖,使之不會重疊
sns.catplot(data=tips, kind="swarm", x="day", y="total_bill", hue="smoker")
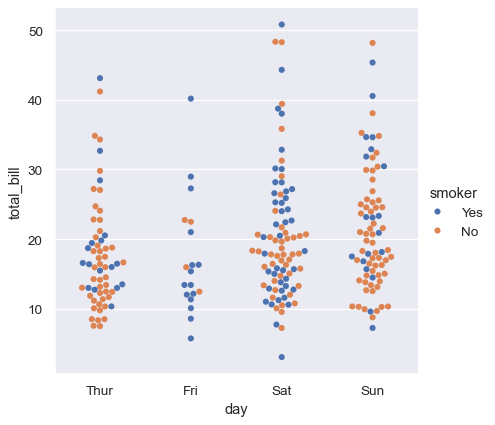
或者,你可以使用核密度估計來表示點取樣的基礎分配
sns.catplot(data=tips, kind="violin", x="day", y="total_bill", hue="smoker", split=True)

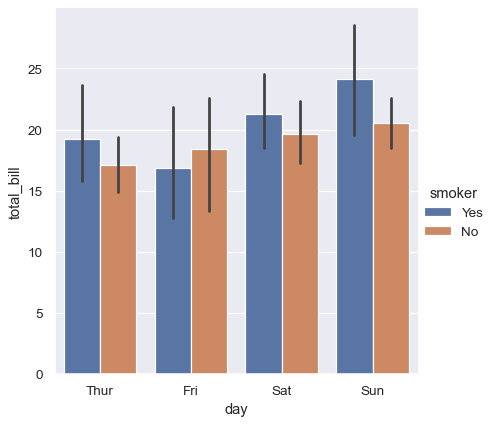
或者你也可以只顯示每個巢狀分類中的平均值及其信賴區間
sns.catplot(data=tips, kind="bar", x="day", y="total_bill", hue="smoker")
對於複雜資料集的多變數檢視#
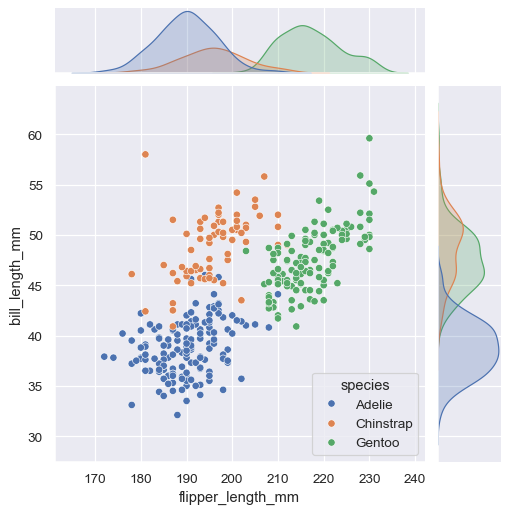
某些 seaborn 函數會合併多種繪圖類型,以便快速提供資料集的資訊性摘要。其中之一,jointplot(),專注於單一關聯關係。它繪製兩個變數之間的聯合分配以及每個變數的邊際分配
penguins = sns.load_dataset("penguins")
sns.jointplot(data=penguins, x="flipper_length_mm", y="bill_length_mm", hue="species")
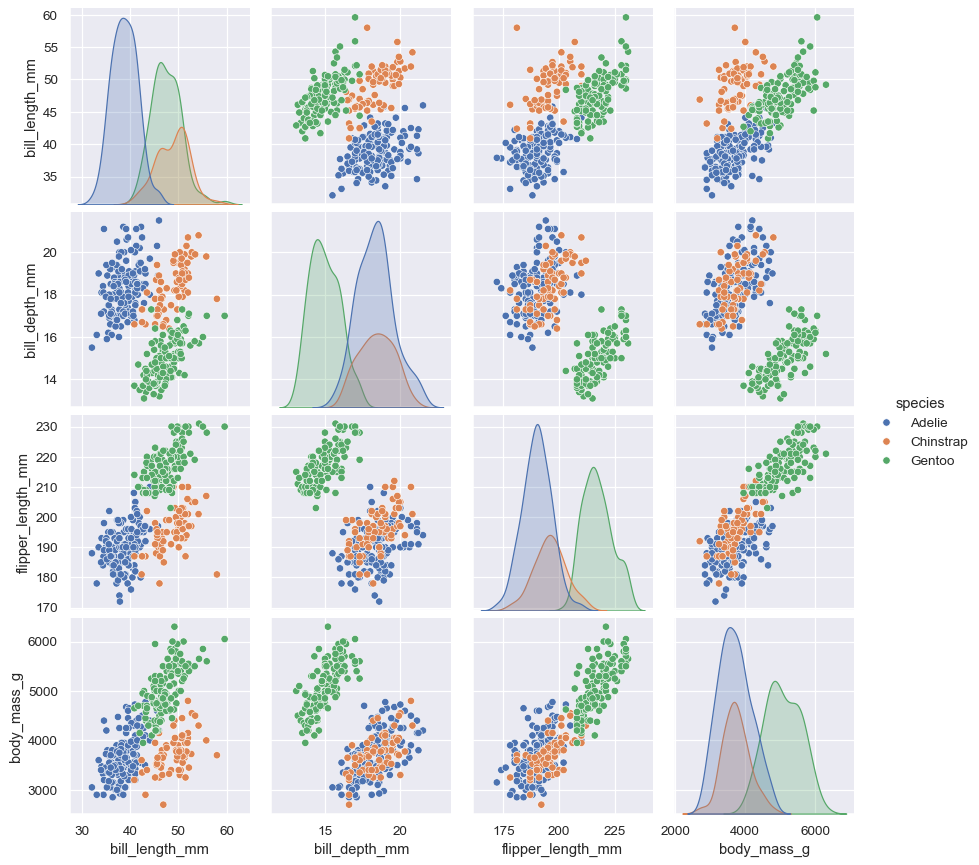
另一項,pairplot(),採取較廣泛的觀點:它分別顯示所有成對關係以及每個變數的聯合和邊際分配
sns.pairplot(data=penguins, hue="species")
用於製作圖表的低階工具#
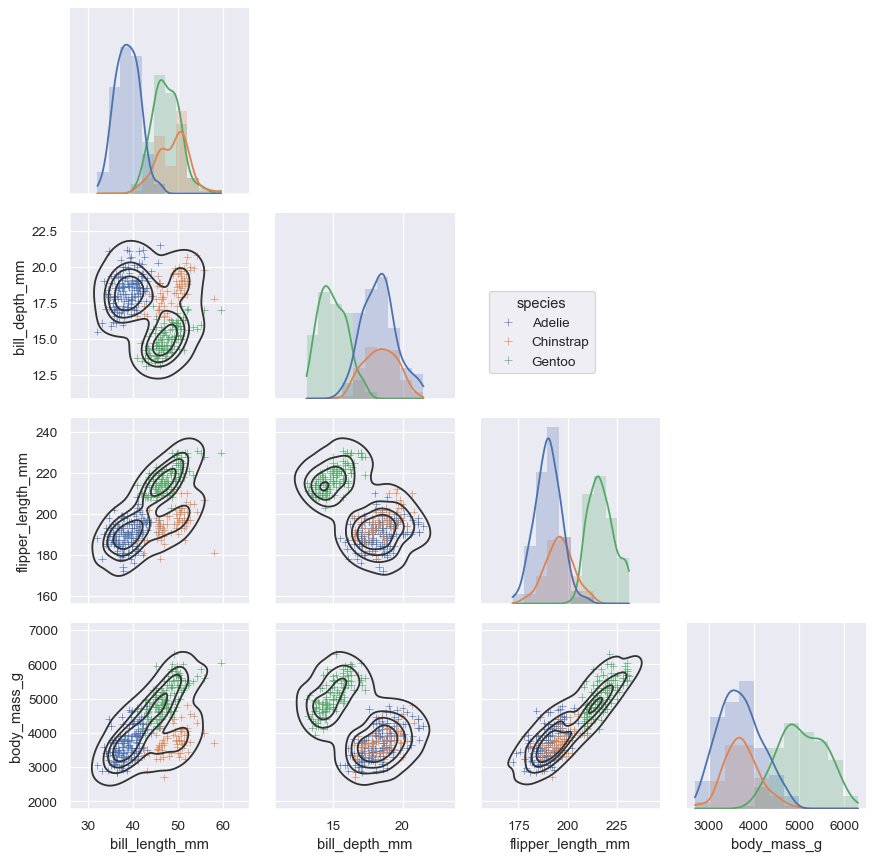
這些工具透過將 軸級數 繪製函數與物件(用於管理圖表的配置,並將資料集的結構連結至 軸方格)結合,以發揮作用。這兩個元素都是公共 API 的一部分,你可以直接使用它們,只需再使用幾行程式碼即可製作複雜的圖表
g = sns.PairGrid(penguins, hue="species", corner=True)
g.map_lower(sns.kdeplot, hue=None, levels=5, color=".2")
g.map_lower(sns.scatterplot, marker="+")
g.map_diag(sns.histplot, element="step", linewidth=0, kde=True)
g.add_legend(frameon=True)
g.legend.set_bbox_to_anchor((.61, .6))
固執己見的預設值與彈性的自訂#
Seaborn 只要呼叫一個函數就可以製作出完整的圖表:有可能的話,其函數會自動加入有資訊性的軸標籤和圖例,說明繪圖中的語義對應。
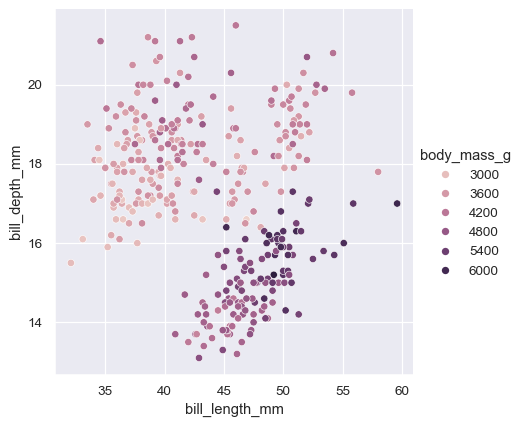
在很多情況下,Seaborn 也會根據資料的特徵為其參數選擇預設值。例如,我們到目前為止所看到的 色彩對應 會使用不同的色調(藍色、橘色,有時是綠色)來表示指定給 色調 的分類變數的不同層級。當對應一個數字變數時,某些函數會轉換為連續漸層
sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g"
)
準備好要分享或發佈您的作品時,您可能會希望將圖形美化,超越預設的目標。Seaborn 提供了好幾個等級的客製化選項。它定義了多個內建 主題,用於套用在所有圖形上,它的函式具有標準化的參數,可以用於修改每個圖形的語意對應,以及額外的關鍵字引數會傳遞給底層的 matplotlib 繪圖者,讓您有更細緻的控制。在建立完一個圖形後,它的屬性可以透過 seaborn API 和降級到 matplotlib 層來修改,以進行細部調整。
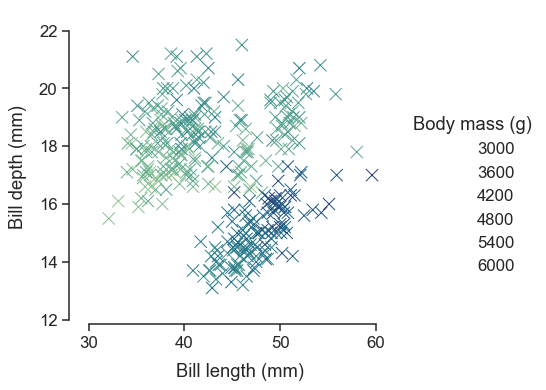
sns.set_theme(style="ticks", font_scale=1.25)
g = sns.relplot(
data=penguins,
x="bill_length_mm", y="bill_depth_mm", hue="body_mass_g",
palette="crest", marker="x", s=100,
)
g.set_axis_labels("Bill length (mm)", "Bill depth (mm)", labelpad=10)
g.legend.set_title("Body mass (g)")
g.figure.set_size_inches(6.5, 4.5)
g.ax.margins(.15)
g.despine(trim=True)
與 matplotlib 的關係#
Seaborn 與 matplotlib 的整合讓您能夠在 matplotlib 支援的許多環境中使用它,包括筆記本中的探索性分析、GUI 應用程式的即時互動,以及多種點陣和向量格式的檔案輸出。
儘管您僅使用 seaborn 函式就能有不錯的生產力,但要完全客製化您的圖形,則需要了解 matplotlib 的概念和 API。對於 seaborn 的新使用者而言,學習曲線的其中一個面向,在於了解何時需要降級到 matplotlib 層,才能達成特定的客製化。另一方面,從 matplotlib 過來的使用者,會發現他們有很多知識可以沿用。
Matplotlib 有一個全面且功能強大的 API;圖形的任何屬性幾乎都可以根據您的喜好進行變更。結合 seaborn 的高階介面和 matplotlib 的深層客製化功能,讓您既可以快速探索資料,也可以建立圖形,並將其調整成 可以刊載 的成品。
後續步驟#
接下來,您有幾個選項。您可能首先要知道如何 安裝 seaborn。完成後,您可以瀏覽 範例庫,以更深入地了解 seaborn 可以製作出哪種類型的圖形。或者,您可以閱讀剩下的 使用者指南和教學課程,針對不同的工具和它們的設計目的深入探討。如果您心中有一個特定的圖形,並想知道如何製作它,您可以查看 API 參考,其中記載了每個函式的參數,並透過許多範例來說明用法。