被 seaborn 接受的資料結構#
作為一個資料視覺化程式庫,seaborn 要求您提供資料。此章節說明達成此任務的不同方法。Seaborn 支援數種不同的資料集格式,而大多數函數接受由 pandas 或 numpy 程式庫的物件表示的資料,以及內建的 Python 類型,例如清單和字典。了解與這些不同選項相關的使用模式,有助於您快速為幾乎任何資料集建立有用的視覺化。
註記
截至目前撰寫 (v0.13.0),本文涵蓋的完整選項廣泛,支援於 seaborn 的大部分函數中,但並非全部。尤其是,幾個較舊的函數(例如 lmplot() 和 regplot())的接受度較有限。
長型資料與寬型資料#
大多數 seaborn 的繪製函數都是針對資料的直線。在針對 x 繪製 y 時,每個變數應為直線。Seaborn 接受組織成表格形式的多個直線的資料集。長型資料表和寬型資料表之間有一項基本區別,而 seaborn 會以不同方式處理兩者。
長型資料#
長型資料表具有下列特徵
每個變數都是一欄
每個觀測都是一列
舉個簡單的範例,考慮「班機」資料集,其中記載了 1949 到 1960 年之間,每個月份搭乘飛機的航空乘客數目。此資料集有三個變數(年份、月份和乘客數量)
flights = sns.load_dataset("flights")
flights.head()
| 年份 | 月份 | 乘客 | |
|---|---|---|---|
| 0 | 1949 | 一月 | 112 |
| 1 | 1949 | 二月 | 118 |
| 2 | 1949 | 三月 | 132 |
| 3 | 1949 | 四月 | 129 |
| 4 | 1949 | 五月 | 121 |
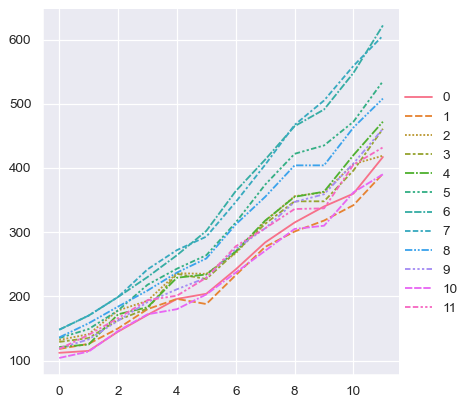
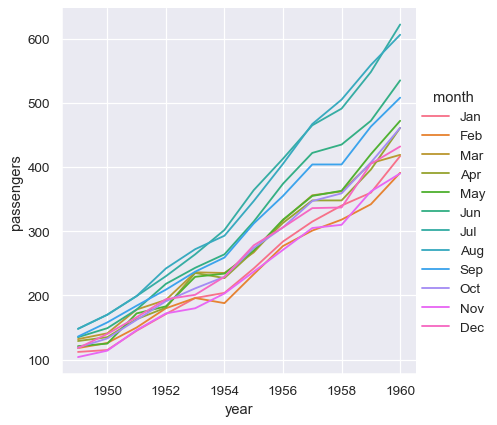
對於長條資料,表格中的資料行基於明確指派給一個變數的原則,在繪製圖表時賦予角色。舉例來說,畫出每年乘客數的月度圖表如下所示
sns.relplot(data=flights, x="year", y="passengers", hue="month", kind="line")
長條資料的優點,在於對於明確指定的繪圖,是一項很適用的資料類型。它可以容納任意複雜的資料集,只要變數和觀測得到明確的定義即可。但是,這種格式需要一些時間來適應,因為它往往不是我們頭腦中的資料模型。
寬表資料#
對於簡單的資料集,通常以電子試算表中的檢視方式思考資料更加直觀,其中資料行的欄位與列包含不同變數的階層。舉例來說,我們可以將班機資料集「樞紐轉換」為寬表組織架構,以便每個資料行擁有針對各年的每個月的時間序列
flights_wide = flights.pivot(index="year", columns="month", values="passengers")
flights_wide.head()
| 月份 | 一月 | 二月 | 三月 | 四月 | 五月 | 六月 | 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 年份 | ||||||||||||
| 1949 | 112 | 118 | 132 | 129 | 121 | 135 | 148 | 148 | 136 | 119 | 104 | 118 |
| 1950 | 115 | 126 | 141 | 135 | 125 | 149 | 170 | 170 | 158 | 133 | 114 | 140 |
| 1951 | 145 | 150 | 178 | 163 | 172 | 178 | 199 | 199 | 184 | 162 | 146 | 166 |
| 1952 | 171 | 180 | 193 | 181 | 183 | 218 | 230 | 242 | 209 | 191 | 172 | 194 |
| 1953 | 196 | 196 | 236 | 235 | 229 | 243 | 264 | 272 | 237 | 211 | 180 | 201 |
這裡有相同的三個變數,但排列方式不同。此資料集中的變數連結到表格的向度,而不是連結到命名欄位。每個觀測都由表格中儲存格的值,以及該儲存格相對於列和資料行索引的座標定義。
使用長條資料,我們可以透過名稱存取資料集中的變數。寬表資料並非如此。儘管如此,由於表格的向度與資料集中的變數之間有清楚的關聯性,因此 seaborn 能夠在繪圖中指派這些變數的角色。
註記
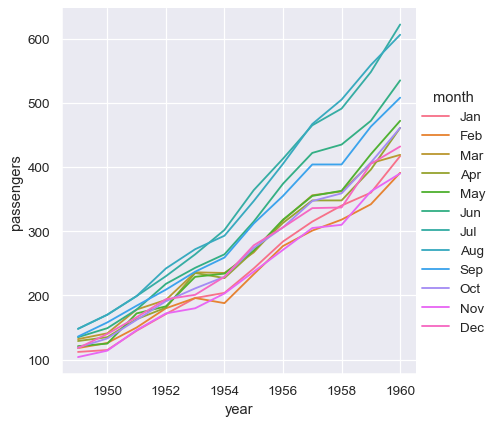
當 x 和 y 皆未指派時,Seaborn 會將 data 的參數視為寬表格式。
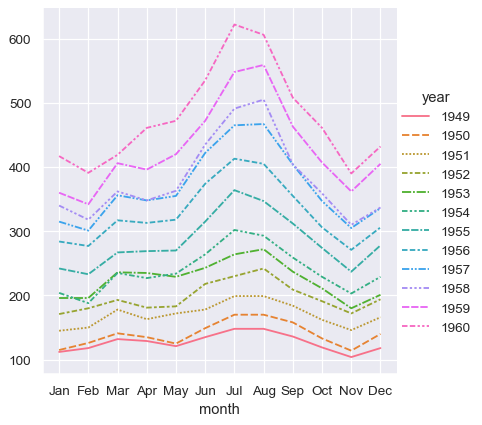
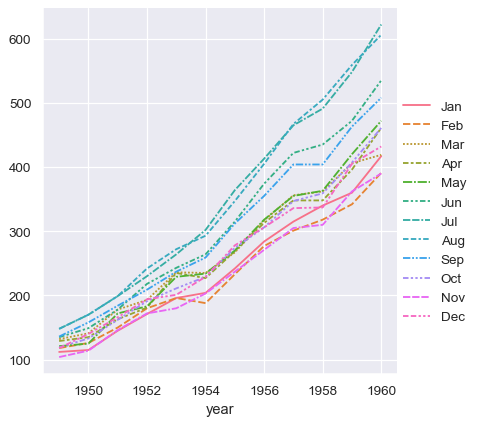
sns.relplot(data=flights_wide, kind="line")
此圖看起來很類似於前一個圖表。Seaborn 已將資料框的索引指派給 x,資料框的值指派給 y,並為每個月份繪製一條獨立的線。不過,這兩個圖表之間有一個顯著的差異。當資料集經過將其從長型表單轉換成寬型表單的「樞紐」運算時,數值含義的資訊就遺失了。因此,沒有 y 軸標籤。(在此,線條也有虛線,這是因為 relplot() 已將資料行欄位對應到 hue 和 style 兩個語意,讓圖表更易於存取。我們沒有在長型表單範例中這麼做,但我們可以透過設定 style="month" 這麼做)。
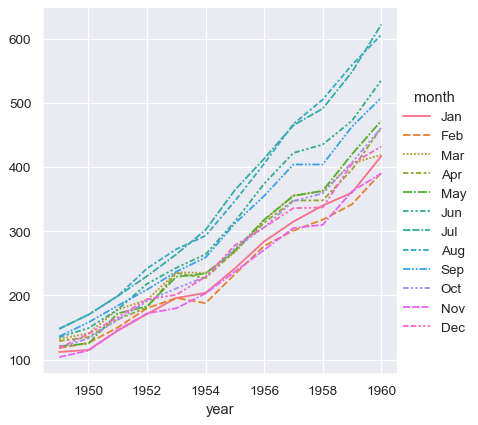
到目前為止,我們在使用寬型表單資料時輸入的內容少很多,而且製出的圖表幾乎相同。這看起來比較容易!但是,長型表單資料的一大優點是,一旦資料有正確的格式,就不再需要思考它的結構。你可以只思考其中包含的變數,就能設計你的圖表。舉例來說,若要繪製代表各年每月時間序列的線條,只要重新指派這些變數即可
sns.relplot(data=flights, x="month", y="passengers", hue="year", kind="line")
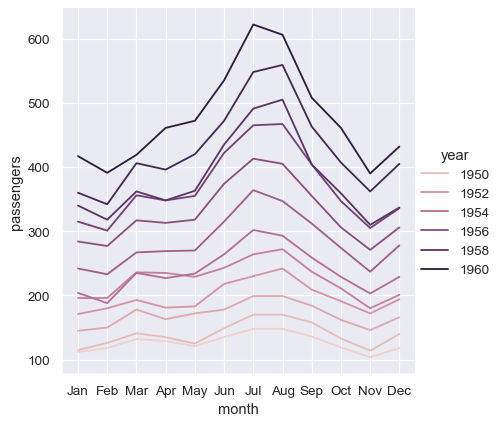
若要對寬型表單資料集取得相同的重新對應,我們需要轉置表格
sns.relplot(data=flights_wide.transpose(), kind="line")
(這個範例也說明了另一個問題,即儘管 Seaborn 目前會根據資料型別視寬型表單資料集中的資料行欄位為類別型,但由於長型表單的變數為數值,因此會指派量化色彩調色盤和圖例。這可能會在未來有所改變)。
沒有明確的變數指派也表示每種類型的圖表都需要針對寬型表單資料的各個維度與圖表角色定義固定的對應。由於這項自然對應可能因圖表類型而異,因此在使用寬型表單資料時,結果的可預測性較差。舉例來說,類別型 圖表會將表格的資料行維度指派為 x,然後在列之間進行匯總(略過索引)
sns.catplot(data=flights_wide, kind="box")
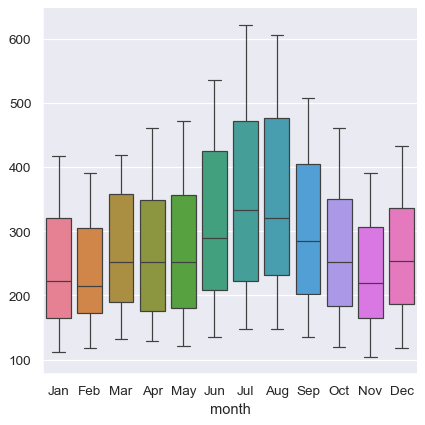
使用 Pandas 來呈現寬格式資料時,你只能使用少數變數(不超過三個)。這是因為 Seaborn 沒有使用多重索引資訊,這是 Pandas 在表格格式中呈現其他變數的方式。 xarray 專案提供有標籤的 N 維度陣列物件,可以視為將寬格式資料廣義化為更高維度。目前,Seaborn 沒有直接支援 xarray 的物件,不過可以使用 to_pandas 方法將它們轉換成長格式 pandas.DataFrame,然後在 Seaborn 中繪製,就像其他長格式資料集一樣。
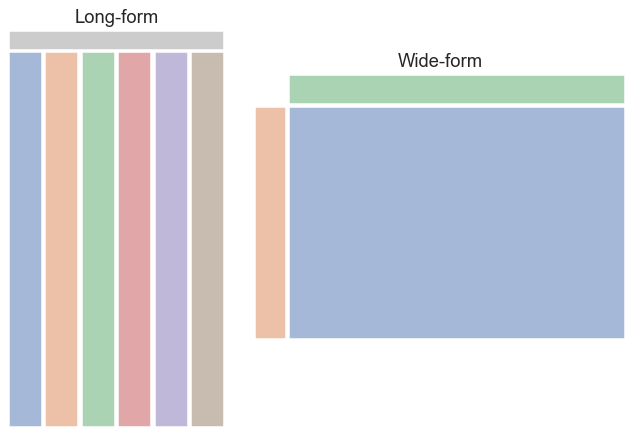
總之,我們可以將長格式和寬格式資料集想像成看起來像這樣
雜亂的資料#
許多資料集無法明確使用長格式或寬格式規則進行詮釋。如果明確的長格式或寬格式資料集是 “整齊的”,我們可以說這些較不明確的資料集是“雜亂的”。在雜亂的資料集中,變數既不是由鍵值唯一定義,也不是由表格的維度定義。這通常發生在重複測量資料,其中自然會組織一個表格,以便每列對應於資料收集的單位。考慮這個心理實驗的簡潔資料集,其中二十個受試者執行了一項記憶工作,他們在注意力分散或專注的情況下研究字謎
anagrams = sns.load_dataset("anagrams")
anagrams
| subidr | attnr | num1 | num2 | num3 | |
|---|---|---|---|---|---|
| 0 | 1 | divided | 2 | 4.0 | 7 |
| 1 | 2 | divided | 3 | 4.0 | 5 |
| 2 | 3 | divided | 3 | 5.0 | 6 |
| 3 | 4 | divided | 5 | 7.0 | 5 |
| 4 | 5 | divided | 4 | 5.0 | 8 |
| 5 | 6 | divided | 5 | 5.0 | 6 |
| 6 | 7 | divided | 5 | 4.5 | 6 |
| 7 | 8 | divided | 5 | 7.0 | 8 |
| 8 | 9 | divided | 2 | 3.0 | 7 |
| 9 | 10 | divided | 6 | 5.0 | 6 |
| 10 | 11 | focused | 6 | 5.0 | 6 |
| 11 | 12 | focused | 8 | 9.0 | 8 |
| 12 | 13 | focused | 6 | 5.0 | 9 |
| 13 | 14 | focused | 8 | 8.0 | 7 |
| 14 | 15 | focused | 8 | 8.0 | 7 |
| 15 | 16 | focused | 6 | 8.0 | 7 |
| 16 | 17 | focused | 7 | 7.0 | 6 |
| 17 | 18 | focused | 7 | 8.0 | 6 |
| 18 | 19 | focused | 5 | 6.0 | 6 |
| 19 | 20 | focused | 6 | 6.0 | 5 |
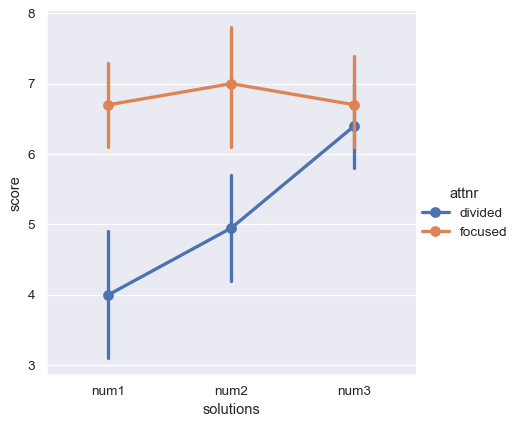
注意力變數是受試者間變數,但也有一個受試者內變數:字謎可能的解法數量,介於 1 到 3。依變數是記憶表現分數。這兩個變數(數量和分數)在多個欄中共用編碼。結果是,整個資料集既不是明確的長格式,也不是明確的寬格式。
我們該如何告訴 Seaborn 將平均分數繪製為注意力和解法數量的函數?我們首先需要將資料轉換為我們的兩個結構之一。讓我們將它轉換成整齊的長格式表格,每個變數為一欄,每列為一個觀察。我們可以使用 pandas.DataFrame.melt() 方法來完成此任務
anagrams_long = anagrams.melt(id_vars=["subidr", "attnr"], var_name="solutions", value_name="score")
anagrams_long.head()
| subidr | attnr | solutions | score | |
|---|---|---|---|---|
| 0 | 1 | divided | num1 | 2.0 |
| 1 | 2 | divided | num1 | 3.0 |
| 2 | 3 | divided | num1 | 3.0 |
| 3 | 4 | divided | num1 | 5.0 |
| 4 | 5 | divided | num1 | 4.0 |
現在我們可以製作我們想要的繪圖
sns.catplot(data=anagrams_long, x="solutions", y="score", hue="attnr", kind="point")
進一步閱讀和重點提示#
要更深入討論表格資料結構,您可以閱讀 Hadley Wickham 撰寫的“資料整潔化” 論文。請注意,seaborn 所使用的概念集與論文中定義的略有不同。儘管論文將資料整潔化與長方形結構聯繫在一起,但我們區分了“資料整齊的寬表格式”,其中資料集中的變數與表格的維度之間有明確的對應關係,以及“混亂的資料”,其中不存在這樣的對應關係。
長方形結構有明顯的優點。它允許您透過明確將資料集中的變數指派到繪圖角色來製作圖表,而且您使用超過三個變數也可以這麼做。若有可能,在進行嚴肅的分析時,請嘗試使用長方形結構來呈現您的資料。seaborn 文件中的大多數範例都將採用長方形的資料。但在資料集保持寬表格式較為自然的情況下,請務必記住 seaborn 仍然是有用的。
視覺化長方形資料的選項#
儘管長方形資料有精確的定義,但 seaborn 在如何透過記憶體中的資料結構實際組織長方形資料方面相當靈活。在本文件其餘部分的範例通常會使用pandas.DataFrame 物件,並透過將其欄位的名稱指派給繪圖中的變數來參照其中的變數。但也可以將向量儲存在 Python 詞典中,或是一個實作該介面的類別中
flights_dict = flights.to_dict()
sns.relplot(data=flights_dict, x="year", y="passengers", hue="month", kind="line")
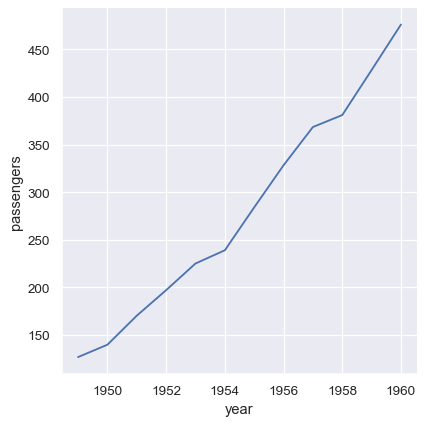
許多 pandas 作業,例如 group-by 的分割-套用-組合作業,將會產生一個資料框,其中資料已從輸入資料框的欄位轉移到輸出的索引標記中。只要名稱保留,您仍然可以照常參照這些資料
flights_avg = flights.groupby("year").mean(numeric_only=True)
sns.relplot(data=flights_avg, x="year", y="passengers", kind="line")
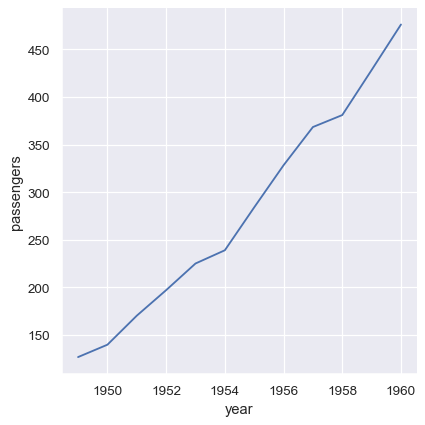
此外,也可以將資料向量直接作為引數傳遞給 x、y 和其他繪圖變數。如果這些向量是 pandas 物件,name 屬性將會用於標記繪圖
year = flights_avg.index
passengers = flights_avg["passengers"]
sns.relplot(x=year, y=passengers, kind="line")
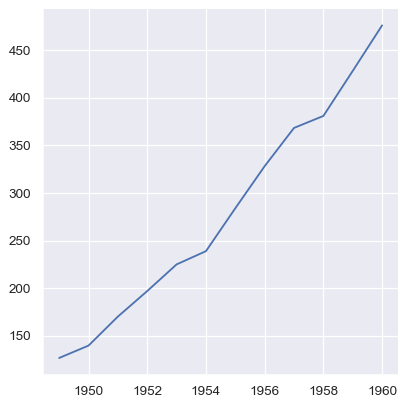
NumPy 陣列和實作 Python 順序介面的其他物件也適用,但如果它們沒有名稱,就需要進一步調整,否則繪圖不會那麼具有資訊性
sns.relplot(x=year.to_numpy(), y=passengers.to_list(), kind="line")
視覺化寬表格式資料的選項#
傳遞寬式資料的選項更具彈性。與長式資料一樣,建議使用 pandas 物件,因為可以利用名稱(且在某些情況下包括索引)資訊。但基本上,任何可以視為單一向量或一組向量的格式都可以傳遞給 data,通常都能產生有效的繪圖。
我們在上方看到的範例使用了矩形 pandas.DataFrame,它可以想像成是一個其欄位的集合。pandas 物件的字典或清單也會運作,但我們會遺失座標軸標籤
flights_wide_list = [col for _, col in flights_wide.items()]
sns.relplot(data=flights_wide_list, kind="line")
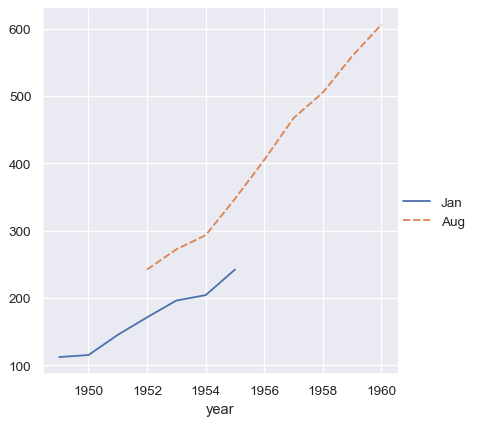
集合中的向量不需要具有相同長度。如果它們有 index,系統會用來對它們做對齊
two_series = [flights_wide.loc[:1955, "Jan"], flights_wide.loc[1952:, "Aug"]]
sns.relplot(data=two_series, kind="line")
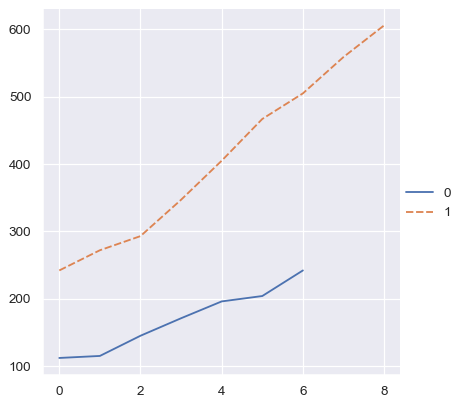
而序數索引將用於 Numpy 陣列或 Python 簡單序列
two_arrays = [s.to_numpy() for s in two_series]
sns.relplot(data=two_arrays, kind="line")
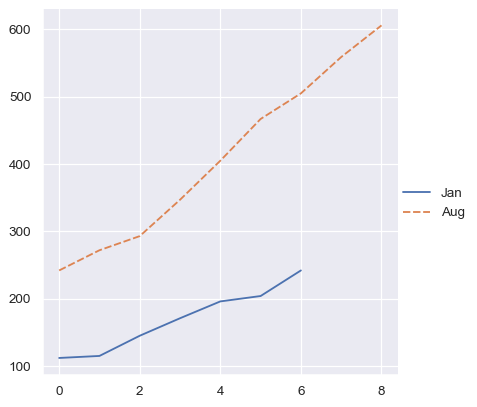
但這類向量的字典至少會使用金鑰
two_arrays_dict = {s.name: s.to_numpy() for s in two_series}
sns.relplot(data=two_arrays_dict, kind="line")
矩形 Numpy 陣列的處理方式就像沒有索引資訊的資料框架一樣,它們被視為一個欄位向量的集合。請注意,這與 Numpy 編制索引運算式的運作方式不同,其中單一編制索引值會存取一行。但它與 pandas 將陣列轉換為資料框架或 matplotlib 用來繪製陣列的方式是一致的
flights_array = flights_wide.to_numpy()
sns.relplot(data=flights_array, kind="line")