seaborn.regplot#
- seaborn.regplot(data=None, *, x=None, y=None, x_estimator=None, x_bins=None, x_ci='ci', scatter=True, fit_reg=True, ci=95, n_boot=1000, units=None, seed=None, order=1, logistic=False, lowess=False, robust=False, logx=False, x_partial=None, y_partial=None, truncate=True, dropna=True, x_jitter=None, y_jitter=None, label=None, color=None, marker='o', scatter_kws=None, line_kws=None, ax=None)#
繪製資料和線性迴歸模型擬合。
有多個互斥的選項可用於估計迴歸模型。請參閱教學以了解更多資訊。
- 參數:
- x, y: 字串、序列或向量陣列
輸入變數。如果為字串,則應與
data中的欄名稱對應。當使用 pandas 物件時,軸將以序列名稱標記。- dataDataFrame
整潔(「長格式」)的資料框架,其中每欄都是一個變數,而每列都是一個觀察值。
- x_estimator將向量對應至純量的可呼叫對象,選用
將此函數套用至每個唯一的
x值,並繪製產生的估計值。當x是離散變數時,這非常有用。如果給定x_ci,則將會執行此估計值的自助法,並繪製信賴區間。- x_bins整數或向量,選用
將
x變數劃分為離散的箱,然後估計集中趨勢和信賴區間。此分箱僅會影響散佈圖的繪製方式;迴歸仍然適用於原始資料。此參數會被解譯為均勻大小(不必間隔)的箱數或箱中心的定位。當使用此參數時,表示x_estimator的預設值為numpy.mean。- x_ci「ci」、「sd」、[0, 100] 中的整數或 None,選用
在繪製
x的離散值的集中趨勢時所使用的信賴區間大小。如果為"ci",則延遲到ci參數的值。如果為"sd",則略過自助法並顯示每個箱中觀察值的標準差。- scatter布林值,選用
如果為
True,則繪製具有基礎觀察值(或x_estimator值)的散佈圖。- fit_reg布林值,選用
如果為
True,則估計並繪製與x和y變數相關的迴歸模型。- ci[0, 100] 中的整數或 None,選用
迴歸估計的信賴區間大小。這將會使用迴歸線周圍的半透明帶繪製。信賴區間是使用自助法估計的;對於大型資料集,建議將此參數設定為 None 來避免計算。
- n_boot整數,選用
用於估計
ci的自助法重取樣次數。預設值嘗試平衡時間和穩定性;您可能需要增加此值以獲得繪圖的「最終」版本。- units
data中的變數名稱,選用 如果
x和y的觀察值巢套在抽樣單元中,則可以在此處指定這些單元。這將在計算信賴區間時列入考量,方法是執行多層次自助法,該自助法會對單元和觀察值(在單元內)進行重取樣。這不會以其他方式影響迴歸的估計或繪製方式。- seed整數、numpy.random.Generator 或 numpy.random.RandomState,選用
用於可重複自助法的種子或隨機數字產生器。
- order整數,選用
如果
order大於 1,則使用numpy.polyfit來估計多項式迴歸。- logisticbool,選用
如果為
True,則假設y是一個二元變數,並使用statsmodels來估計邏輯迴歸模型。 請注意,這比線性迴歸在計算上密集得多,因此您可能希望減少 bootstrap 重採樣的次數(n_boot)或將ci設定為 None。- lowessbool,選用
如果為
True,則使用statsmodels來估計非參數 lowess 模型(局部加權線性迴歸)。 請注意,目前無法為此類模型繪製信賴區間。- robustbool,選用
如果為
True,則使用statsmodels來估計穩健迴歸。 這將降低離群值的權重。 請注意,這比標準線性迴歸在計算上密集得多,因此您可能希望減少 bootstrap 重採樣的次數(n_boot)或將ci設定為 None。- logxbool,選用
如果為
True,則估計 y ~ log(x) 形式的線性迴歸,但在輸入空間中繪製散佈圖和迴歸模型。 請注意,x必須為正數才能使其運作。- {x,y}_partial
data中的字串或矩陣 在繪圖之前,要從
x或y變數中迴歸去除的干擾變數。- truncatebool,選用
如果為
True,則迴歸線會受資料限制所限制。如果為False,則會延伸到x軸的限制。- {x,y}_jitter浮點數,選用
將此大小的均勻隨機雜訊加入到
x或y變數中。 在擬合迴歸後,雜訊會加入到資料的副本中,並且只會影響散佈圖的外觀。 當繪製取離散值的變數時,這可能會很有幫助。- label字串
要套用至散佈圖或迴歸線(如果
scatter為False)的標籤,以便在圖例中使用。- colormatplotlib 顏色
要套用至所有繪圖元素的顏色;將會被傳入
scatter_kws或line_kws中的顏色取代。- markermatplotlib 標記代碼
用於散佈圖符號的標記。
- {scatter,line}_kws字典
要傳遞給
plt.scatter和plt.plot的其他關鍵字引數。- axmatplotlib Axes,選用
要將繪圖繪製在其上的 Axes 物件,否則使用目前的 Axes。
- 傳回值:
- axmatplotlib Axes
包含繪圖的 Axes 物件。
另請參閱
注意事項
regplot()和lmplot()函數密切相關,但前者是軸級函數,而後者是圖級函數,結合了regplot()和FacetGrid。透過
jointplot()和pairplot()函數,也很容易結合regplot()和JointGrid或PairGrid,雖然這些函數並非直接接受regplot()的所有參數。範例
繪製 DataFrame 中兩個變數之間的關係
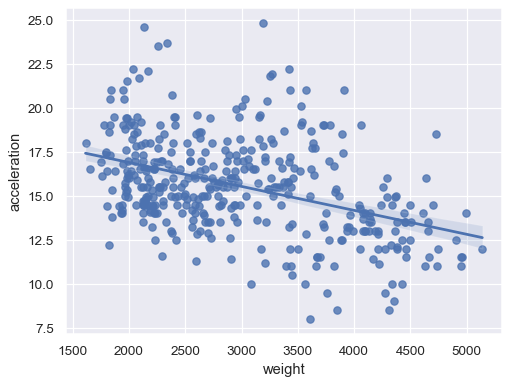
sns.regplot(data=mpg, x="weight", y="acceleration")
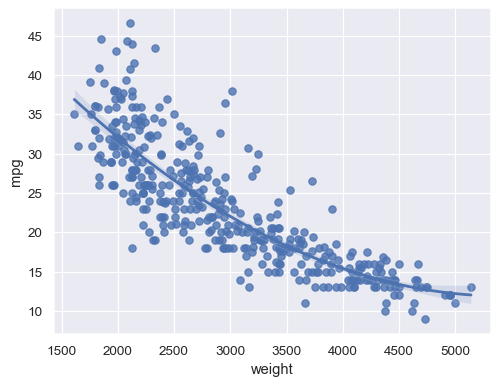
擬合較高階的多項式迴歸以捕捉非線性趨勢
sns.regplot(data=mpg, x="weight", y="mpg", order=2)
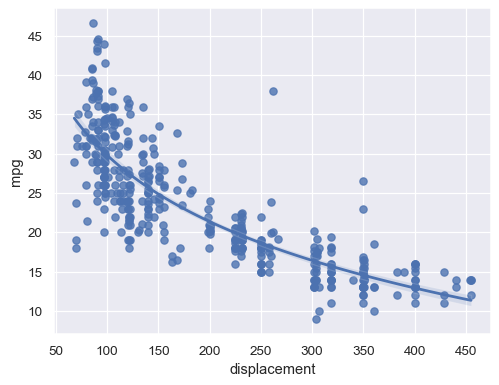
或者,擬合對數線性迴歸
sns.regplot(data=mpg, x="displacement", y="mpg", logx=True)
或使用局部加權 (LOWESS) 平滑器
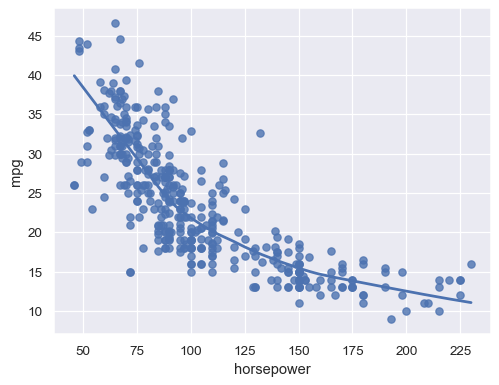
sns.regplot(data=mpg, x="horsepower", y="mpg", lowess=True)
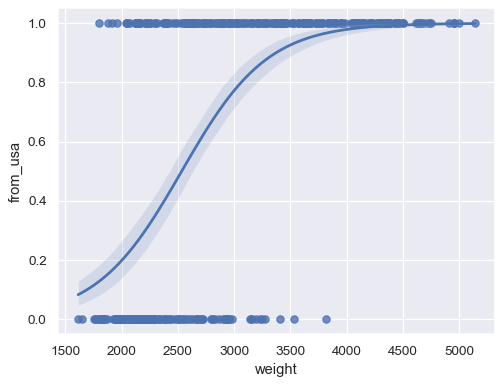
當回應變數為二元時,擬合邏輯迴歸
sns.regplot(x=mpg["weight"], y=mpg["origin"].eq("usa").rename("from_usa"), logistic=True)
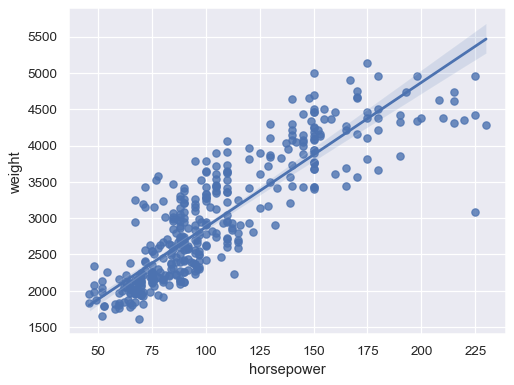
擬合穩健迴歸以降低離群值的影響
sns.regplot(data=mpg, x="horsepower", y="weight", robust=True)
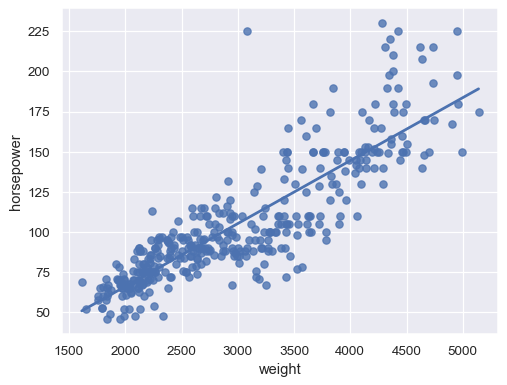
停用信賴區間以加快繪圖速度
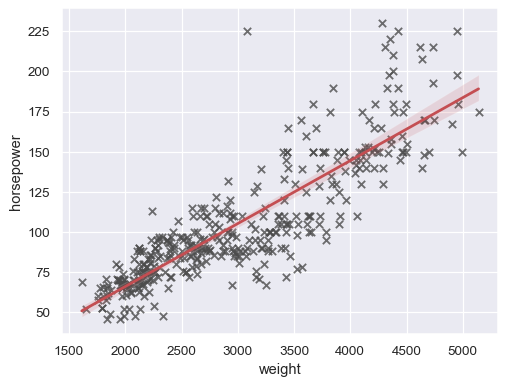
sns.regplot(data=mpg, x="weight", y="horsepower", ci=None)
當
x變數為離散時,抖動散佈圖sns.regplot(data=mpg, x="cylinders", y="weight", x_jitter=.15)
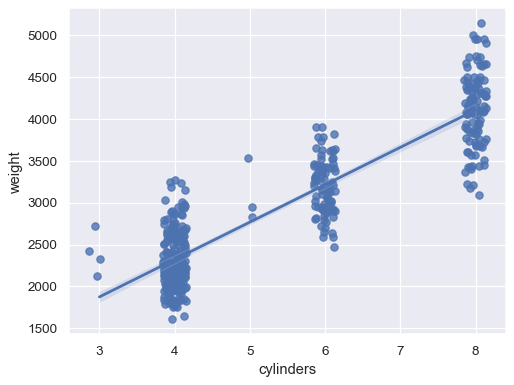
或將不同的
x值彙總sns.regplot(data=mpg, x="cylinders", y="acceleration", x_estimator=np.mean, order=2)
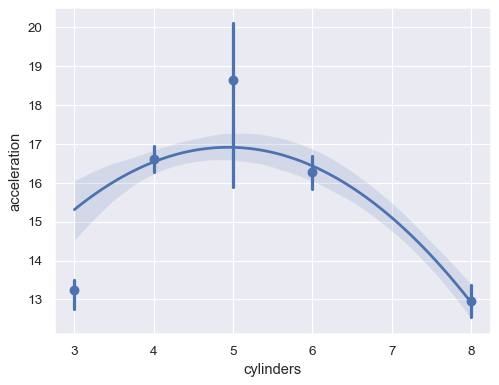
對於連續的
x變數,分箱然後彙總sns.regplot(data=mpg, x="weight", y="mpg", x_bins=np.arange(2000, 5500, 250), order=2)
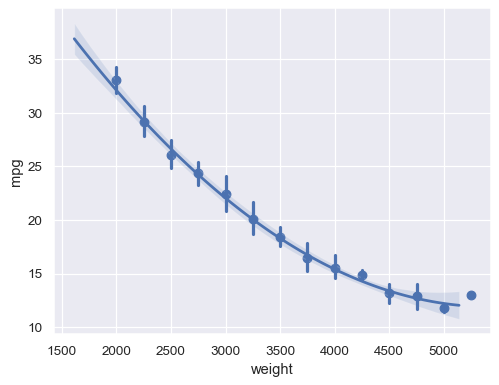
自訂各種元素的外觀
sns.regplot( data=mpg, x="weight", y="horsepower", ci=99, marker="x", color=".3", line_kws=dict(color="r"), )