seaborn.objects.Hist#
- class seaborn.objects.Hist(stat='count', bins='auto', binwidth=None, binrange=None, common_norm=True, common_bins=True, cumulative=False, discrete=False)#
將觀察值分組,計算它們的數量,並選擇性地進行正規化或累積。
- 參數:
- statstr
在每個組距中計算的聚合統計量
count: 觀察值的數量density: 正規化,使直方圖的總面積等於 1percent: 正規化,使長條高度總和為 100probability或proportion: 正規化,使長條高度總和為 1frequency: 將觀察值數量除以組距寬度
- binsstr、int 或 ArrayLike
通用參數,可以是參考規則的名稱、組距的數量或組距的中斷點。傳遞給
numpy.histogram_bin_edges()。- binwidthfloat
每個組距的寬度;覆寫
bins,但可以與binrange一起使用。請注意,如果binwidth無法均勻分割組距範圍,則實際使用的組距寬度將僅約等於參數值。- binrange(min, max)
組距邊緣的最小值和最大值;可以與
bins(當為數字時) 或binwidth一起使用。預設為資料的極端值。- common_normbool 或變數列表
當不是
False時,正規化將應用於各群組。使用True在所有群組中進行正規化,或傳遞定義正規化群組的變數名稱。- common_binsbool 或變數列表
當不是
False時,所有群組都使用相同的組距。使用True在所有群組之間共用組距,或傳遞變數名稱以在其中共用。- cumulativebool
如果為 True,則累積組距值。
- discretebool
如果為 True,則設定
binwidth和binrange,使組距具有單位寬度並以整數值為中心
註解
選擇用於計算和繪製直方圖的組距會對從視覺化中得出見解產生重大影響。如果組距太大,它們可能會抹除重要的特徵。另一方面,組距太小可能會被隨機變異性所支配,從而模糊了真實基礎分佈的形狀。預設的組距大小是使用取決於樣本大小和變異數的參考規則來確定的。這在許多情況下都有效(即,對於「良好行為」的資料),但在其他情況下會失敗。嘗試不同的組距大小以確保您沒有遺漏任何重要內容總是一個好主意。此函數允許您以幾種不同的方式指定組距,例如設定要使用的組距總數、每個組距的寬度或組距應中斷的特定位置。
範例
對於離散或類別變數,此統計量通常與
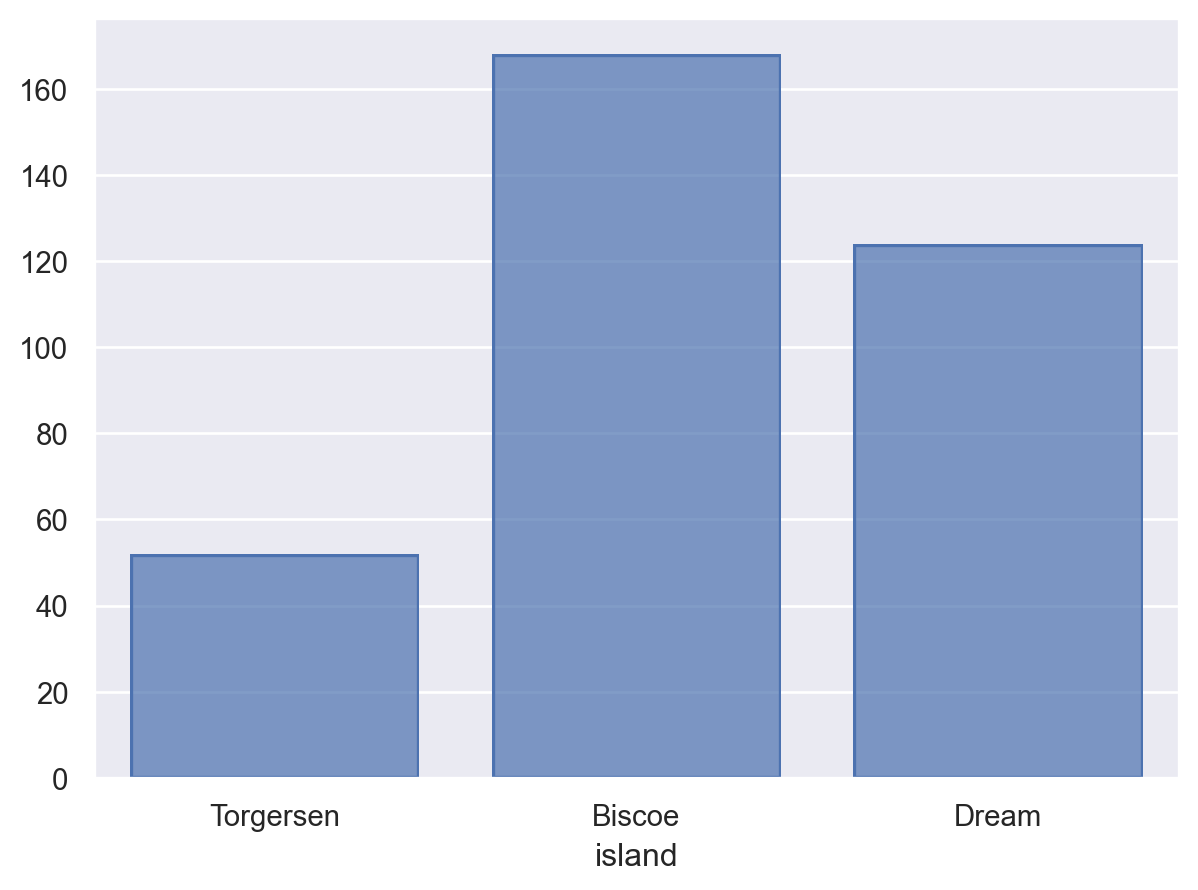
Bar標記結合使用so.Plot(penguins, "island").add(so.Bar(), so.Hist())
當用於估計單變數分佈時,最好使用
Bars標記p = so.Plot(penguins, "flipper_length_mm") p.add(so.Bars(), so.Hist())
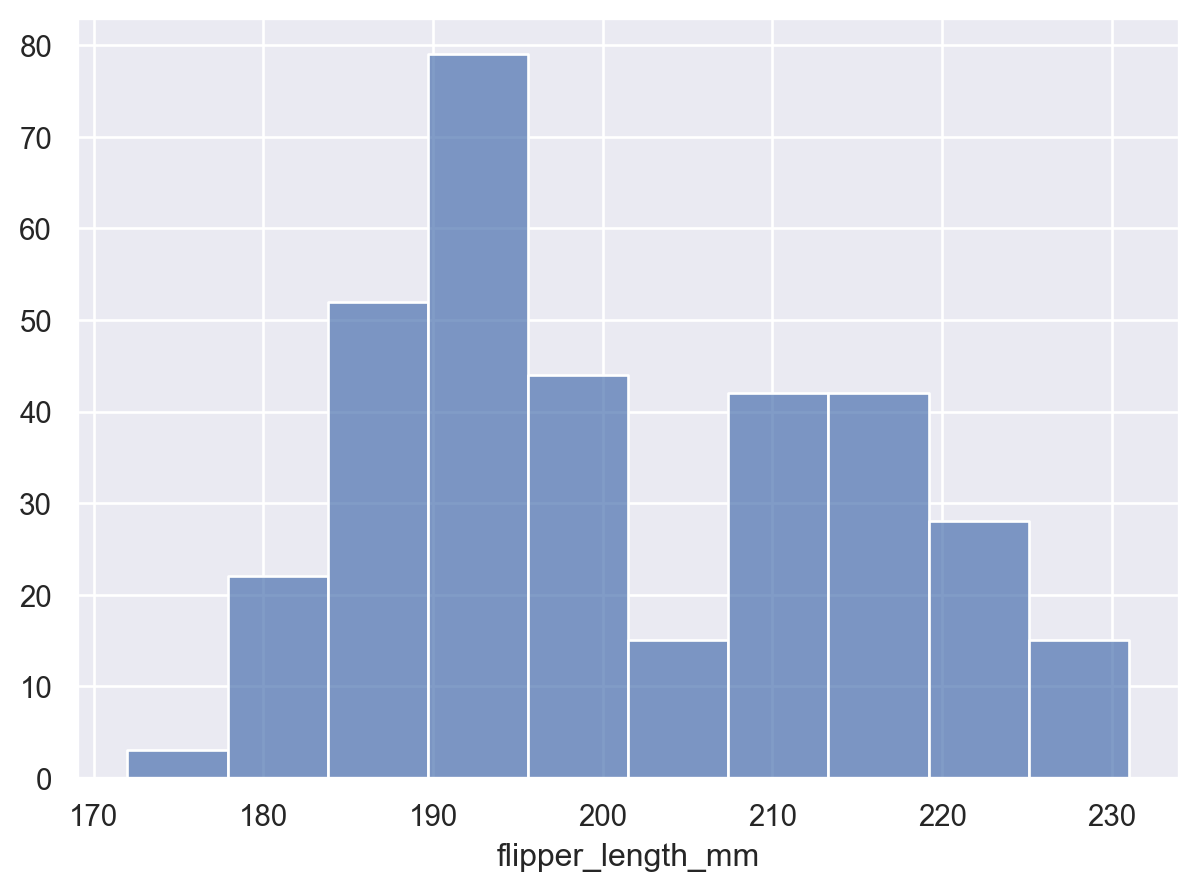
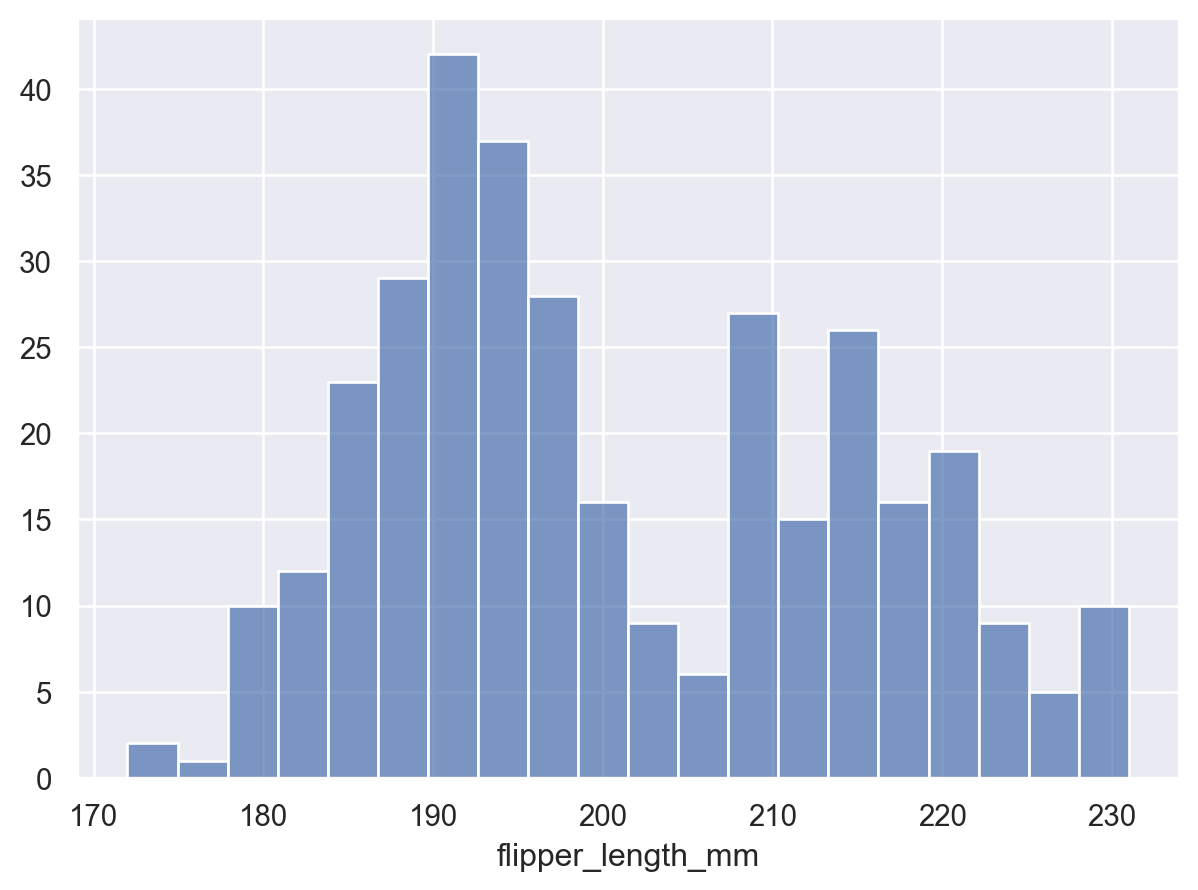
組距的粒度將影響基礎分佈是否被準確表示。透過設定總數來調整它
p.add(so.Bars(), so.Hist(bins=20))
或者,指定組距的寬度
p.add(so.Bars(), so.Hist(binwidth=5))
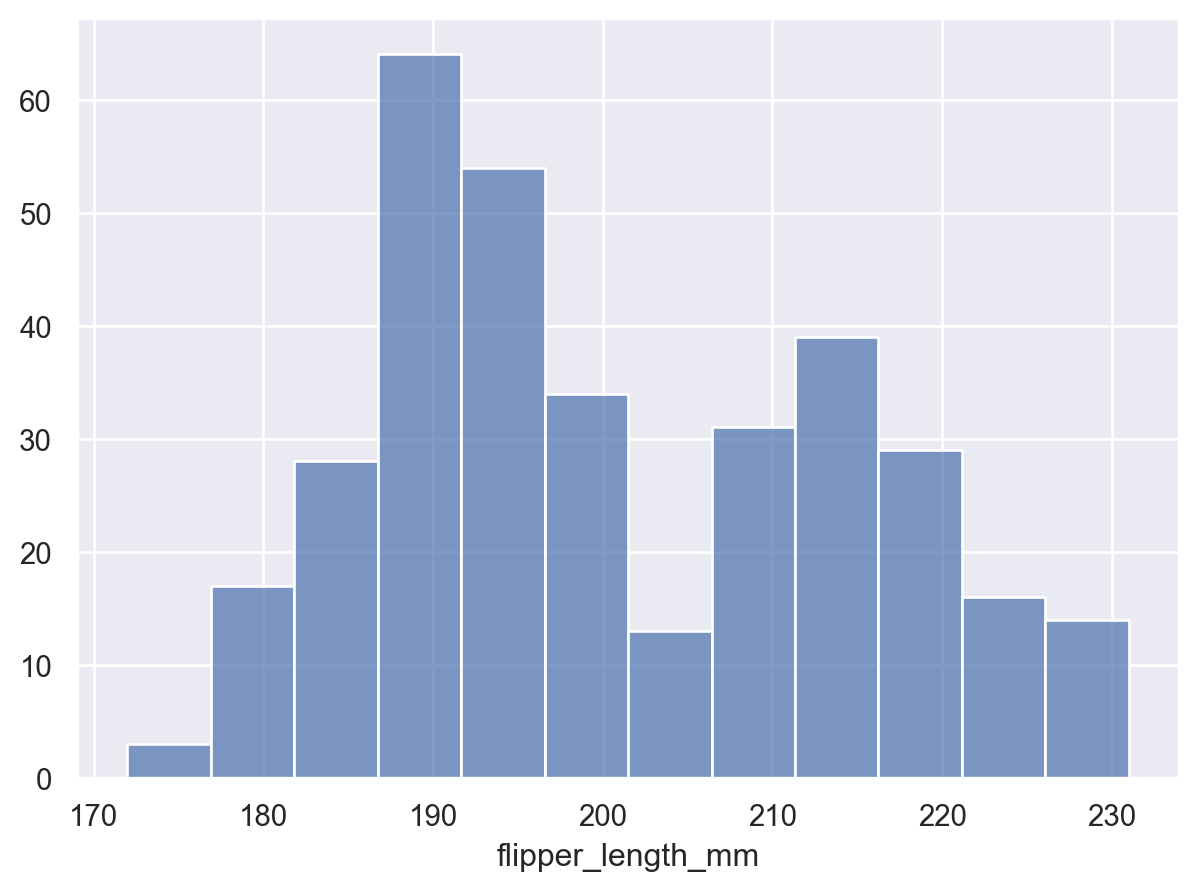
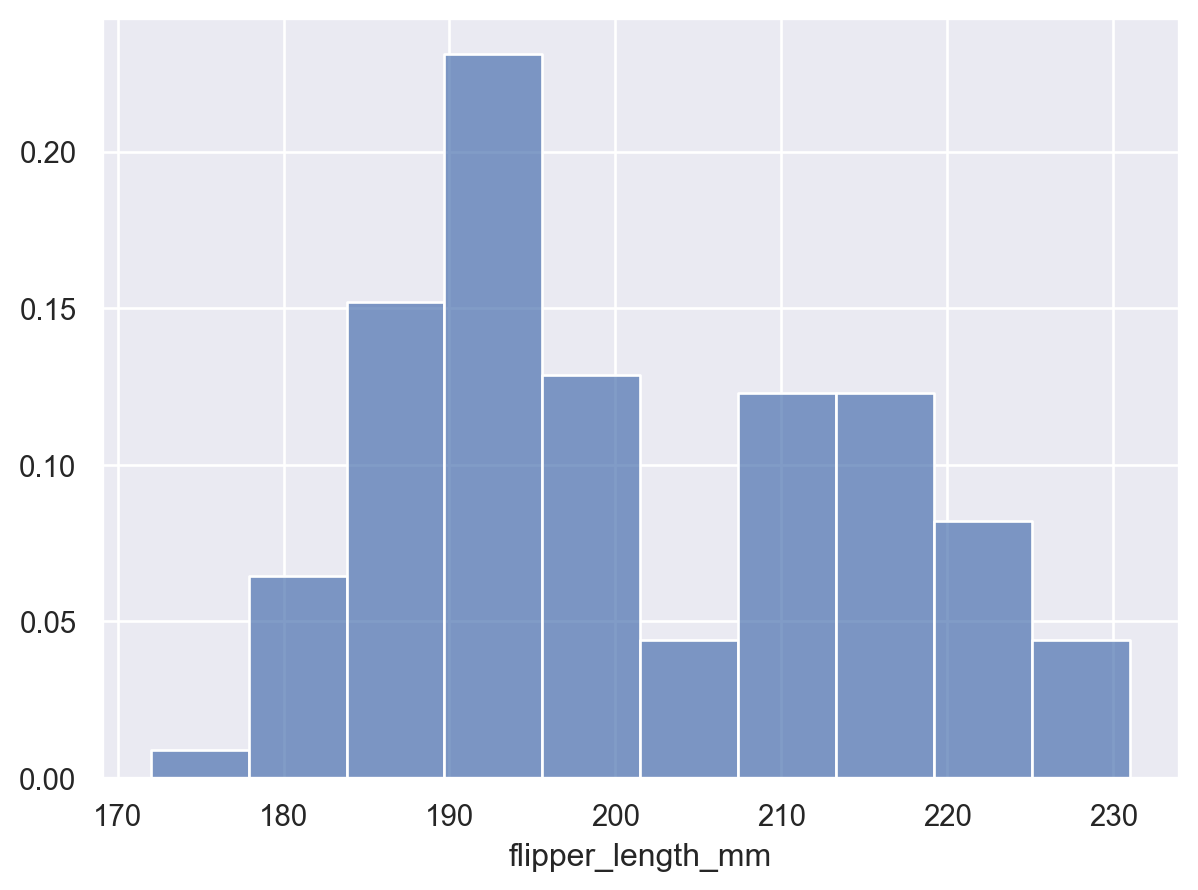
預設情況下,轉換會傳回每個組距中觀察值的計數。可以對計數進行正規化,例如顯示比例
p.add(so.Bars(), so.Hist(stat="proportion"))
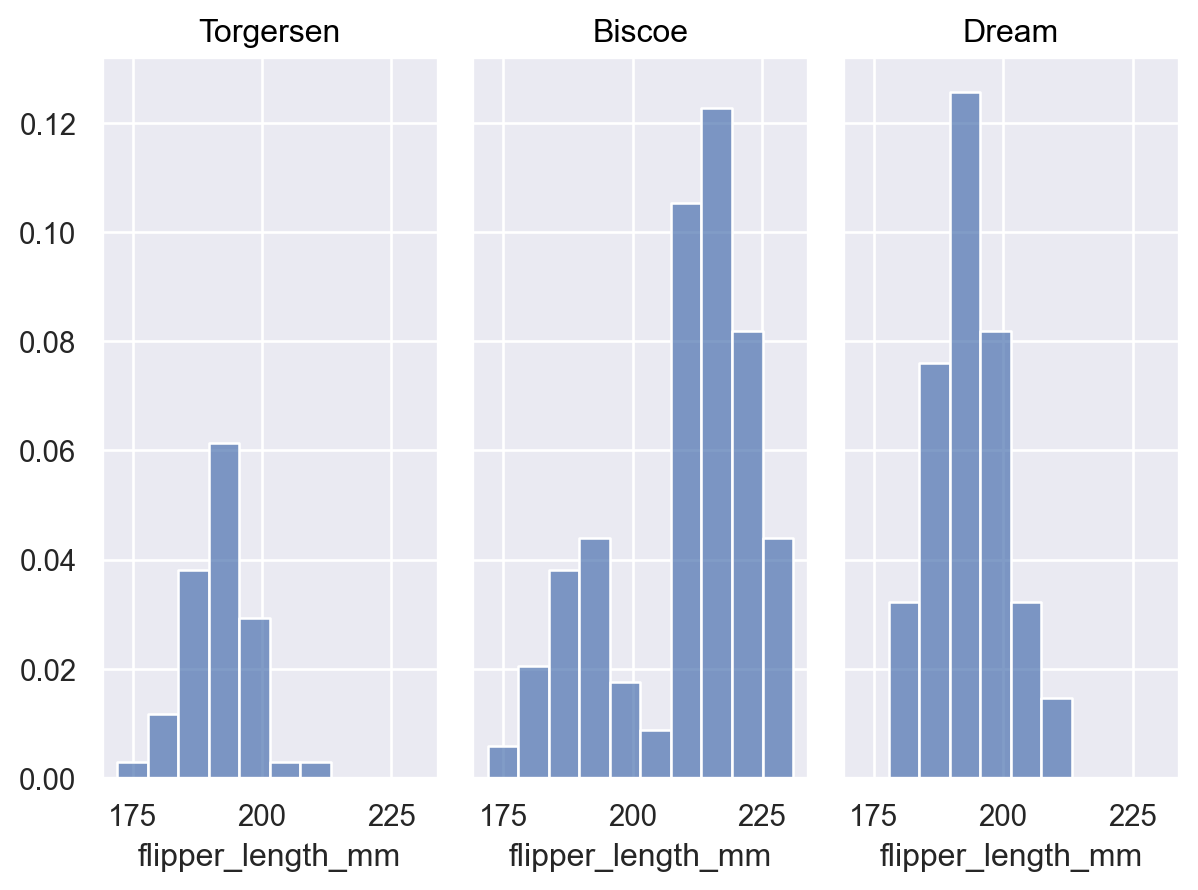
當其他變數定義群組時,預設行為是在所有群組中進行正規化
p = p.facet("island") p.add(so.Bars(), so.Hist(stat="proportion"))
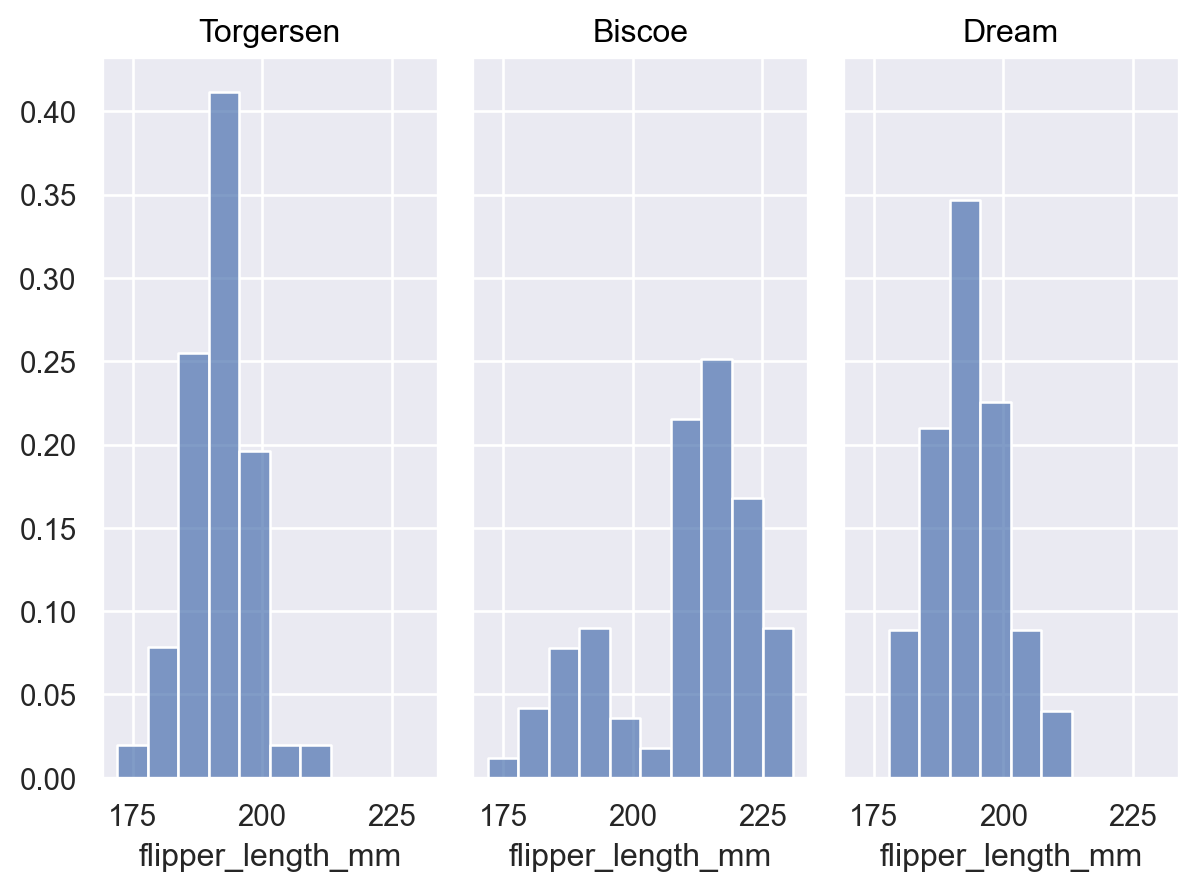
傳遞
common_norm=False以獨立正規化每個分佈p.add(so.Bars(), so.Hist(stat="proportion", common_norm=False))
或者,使用多個分組變數時,指定要在其中進行正規化的子集
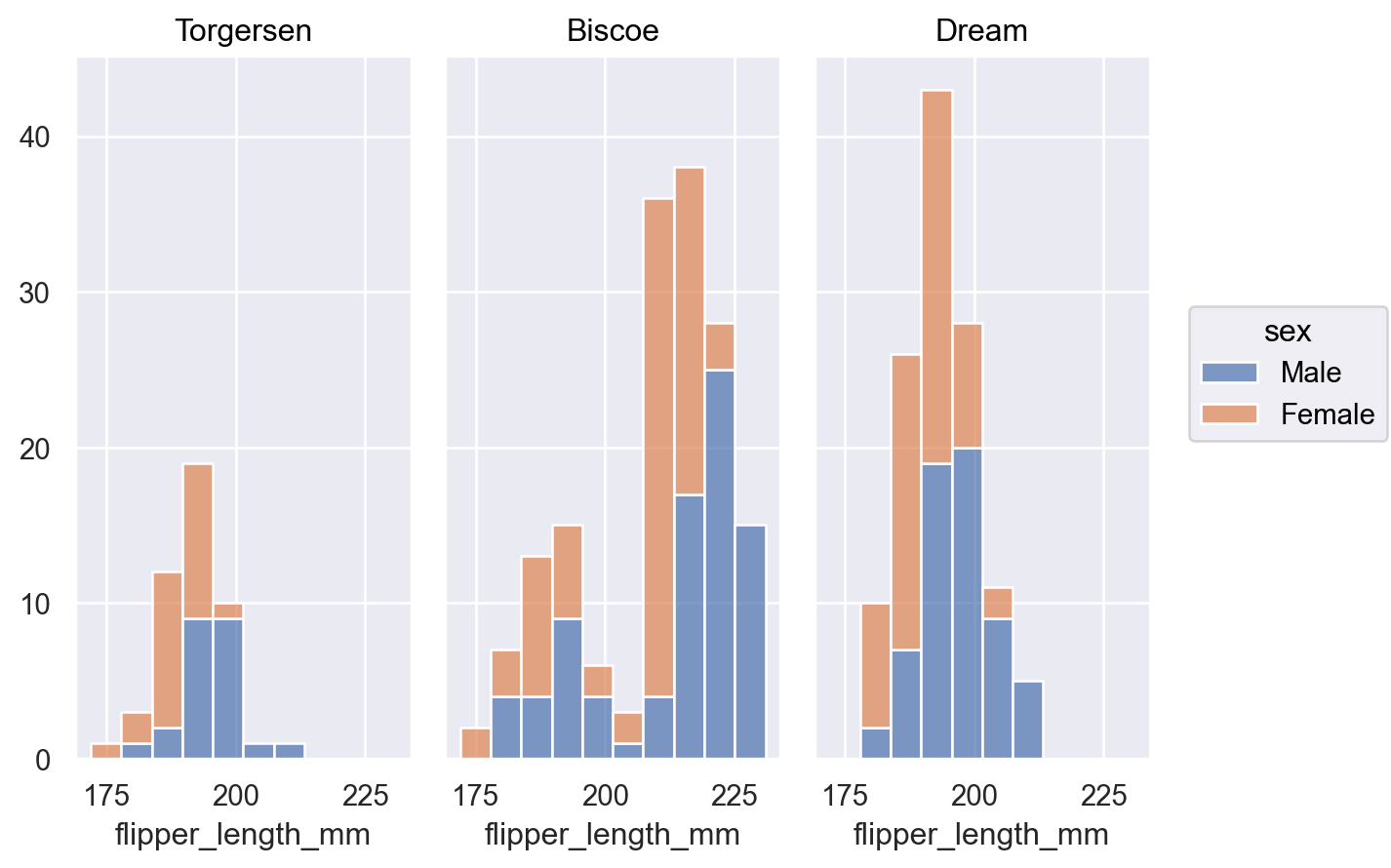
p.add(so.Bars(), so.Hist(stat="proportion", common_norm=["col"]), color="sex")
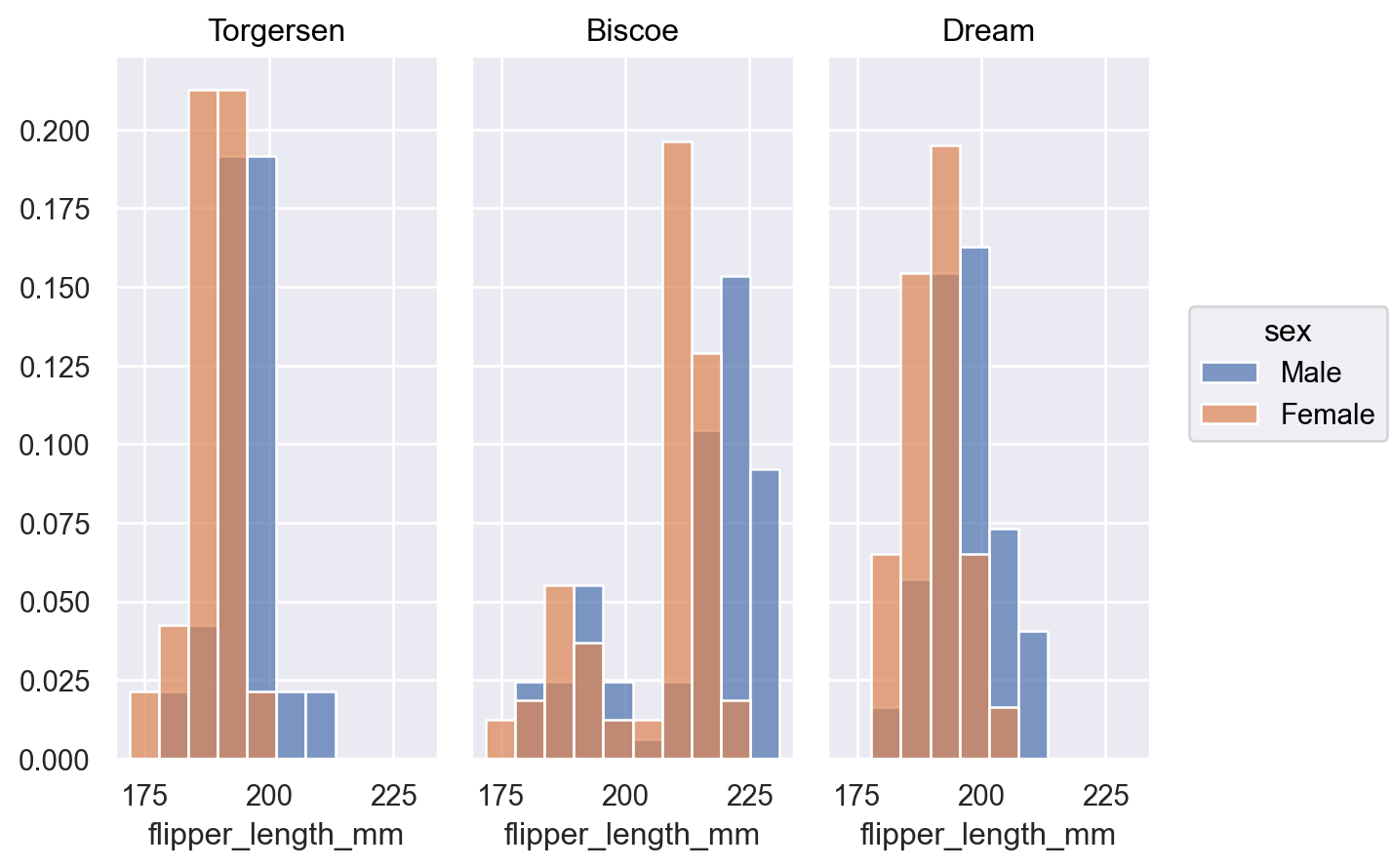
當分佈重疊時,使用
Area標記可能更容易辨別其形狀p.add(so.Area(), so.Hist(), color="sex")
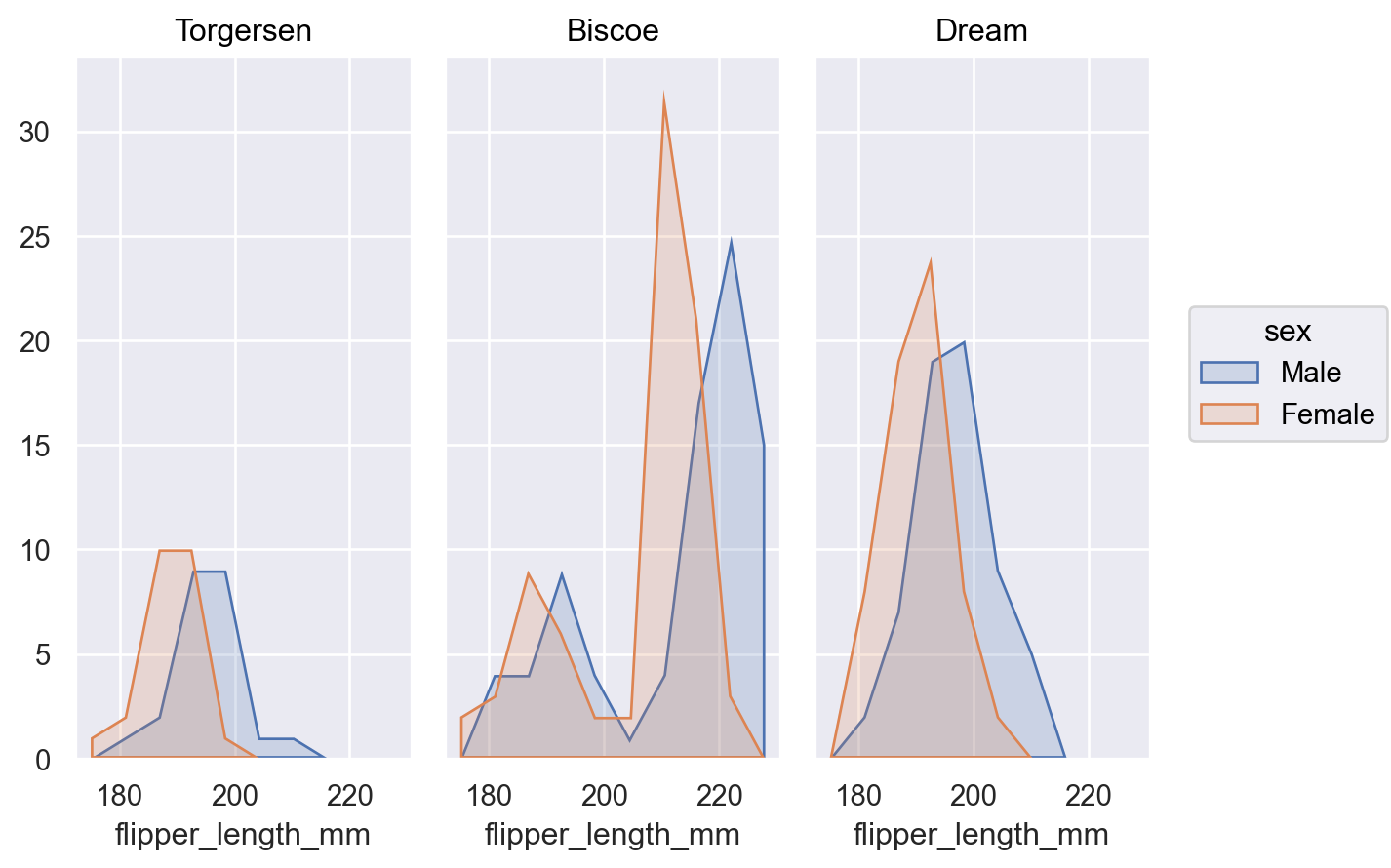
或者,新增
Stack移動以表示部分-整體關係p.add(so.Bars(), so.Hist(), so.Stack(), color="sex")