seaborn.ecdfplot#
- seaborn.ecdfplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='proportion', complementary=False, palette=None, hue_order=None, hue_norm=None, log_scale=None, legend=True, ax=None, **kwargs)#
繪製經驗累積分布函數。
ECDF 代表數據集中每個唯一值以下觀測值的比例或計數。與直方圖或密度圖相比,它的優勢在於每個觀測值都是直接視覺化的,這意味著不需要調整分箱或平滑參數。它也有助於多個分布之間的直接比較。缺點是圖表的外觀與分布的基本屬性(例如其集中趨勢、變異數以及是否存在任何雙峰性)之間的關係可能不那麼直觀。
更多資訊請參閱使用者指南。
- 參數:
- data
pandas.DataFrame、numpy.ndarray、映射或序列 輸入資料結構。可以是可分配給命名變數的長格式向量集合,也可以是將在內部重新塑形的寬格式數據集。
- x, y向量或
data中的鍵 指定 x 軸和 y 軸位置的變數。
- hue向量或
data中的鍵 映射以確定繪圖元素顏色的語義變數。
- weights向量或
data中的鍵 如果提供,則使用這些值權衡相應數據點對累積分布的貢獻。
- stat{{“proportion”, “percent”, “count”}}
要計算的分布統計量。
- complementary布林值
如果為 True,則使用互補 CDF (1 - CDF)
- palette字串、清單、字典或
matplotlib.colors.Colormap 用於在映射
hue語義時選擇顏色的方法。字串值會傳遞給color_palette()。清單或字典值表示類別映射,而色彩對應物件表示數值映射。- hue_order字串向量
指定
hue語義的類別級別的處理和繪圖順序。- hue_norm元組或
matplotlib.colors.Normalize 一組設定數據單位正規化範圍的值,或一個將數據單位映射到 [0, 1] 區間的物件。使用表示數值映射。
- log_scale布林值或數字,或一對布林值或數字
將軸刻度設定為對數。單個值設定圖中任何數值軸的數據軸。一對值獨立設定每個軸。數值被解釋為所需的底數(預設值為 10)。當
None或False時,seaborn 會延後至現有的軸刻度。- legend布林值
如果為 False,則抑制語義變數的圖例。
- ax
matplotlib.axes.Axes 繪圖的預先存在的軸。否則,請在內部呼叫
matplotlib.pyplot.gca()。- kwargs
其他關鍵字參數會傳遞給
matplotlib.axes.Axes.plot()。
- data
- 回傳值:
matplotlib.axes.Axes包含繪圖的 matplotlib 軸。
參見
範例
沿著 x 軸繪製單變數分佈
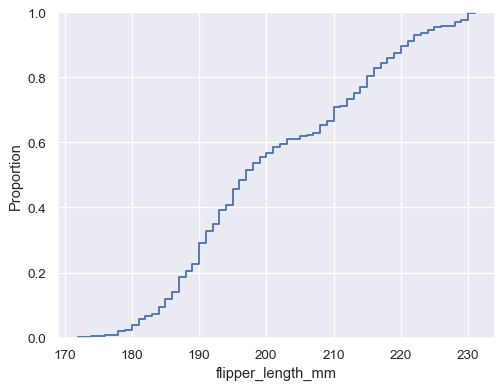
penguins = sns.load_dataset("penguins") sns.ecdfplot(data=penguins, x="flipper_length_mm")
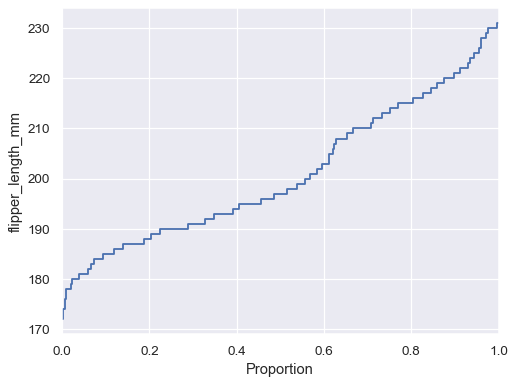
將資料變數指定給 y 軸以翻轉繪圖
sns.ecdfplot(data=penguins, y="flipper_length_mm")
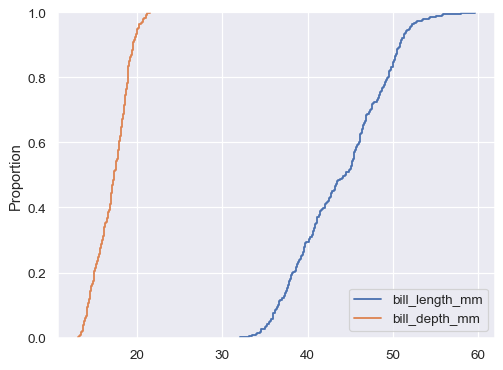
如果未指定
x或y,則資料集會被視為寬格式,並為每個數字列繪製直方圖sns.ecdfplot(data=penguins.filter(like="bill_", axis="columns"))
您也可以從具有色調映射的長格式資料集中繪製多個直方圖
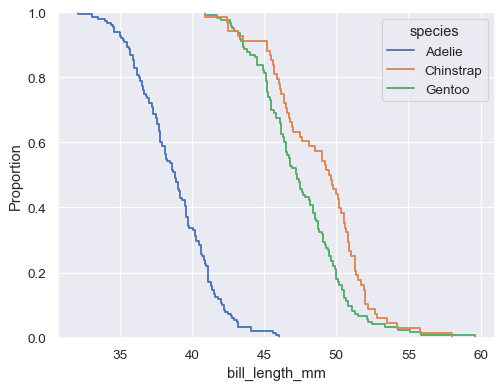
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species")
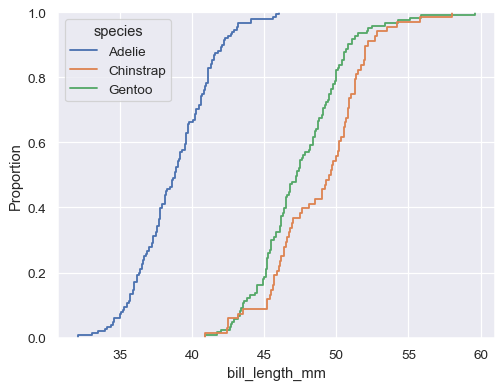
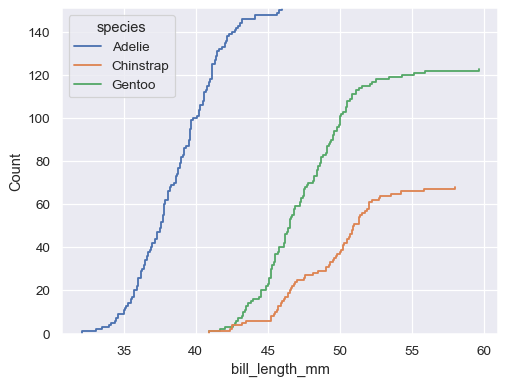
預設分佈統計值會正規化以顯示比例,但您可以顯示絕對計數或百分比
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", stat="count")
也可以繪製經驗互補累積分布函數 (1 - CDF)
sns.ecdfplot(data=penguins, x="bill_length_mm", hue="species", complementary=True)