seaborn.pointplot#
- seaborn.pointplot(data=None, *, x=None, y=None, hue=None, order=None, hue_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, units=None, weights=None, color=None, palette=None, hue_norm=None, markers=<default>, linestyles=<default>, dodge=False, log_scale=None, native_scale=False, orient=None, capsize=0, formatter=None, legend='auto', err_kws=None, ci=<deprecated>, errwidth=<deprecated>, join=<deprecated>, scale=<deprecated>, ax=None, **kwargs)#
使用帶有標記的線條顯示點估計值和誤差。
點圖通過點的位置表示數值變量的集中趨勢估計,並使用誤差條提供該估計值周圍不確定性的一些指示。
對於關注一個或多個類別變量不同級別之間的比較,點圖可能比條形圖更有用。它們尤其擅長顯示交互作用:一個類別變量級別之間的關係如何隨著第二個類別變量的級別而變化。連接相同
hue級別中每個點的線條允許通過斜率的差異來判斷交互作用,這比比較幾組點或條的高度更容易讓眼睛判斷。有關更多信息,請參閱教學。
注意
預設情況下,此函式會將其中一個變量視為類別變量,並在相關軸上的序數位置 (0, 1, … n) 繪製數據。從 0.13.0 版本開始,可以通過設定
native_scale=True來停用此功能。- 參數:
- dataDataFrame、Series、dict、array 或數組列表
用於繪圖的資料集。如果缺少
x和y,則將其解釋為寬格式。否則,預期為長格式。- x, y, hue
data中的變數名稱或向量資料 用於繪製長格式資料的輸入。請參閱範例以進行解釋。
- order, hue_order字串列表
繪製類別級別的順序;否則,級別將從資料物件推斷得出。
- estimator將向量對應到純量的字串或可呼叫物件
在每個類別 bin 內估計的統計函式。
- errorbar字串、「(字串, 數字)」元組、可呼叫物件或 None
誤差條方法的名稱(可以是 "ci"、"pi"、"se" 或 "sd"),或具有方法名稱和層級參數的元組,或從向量對應到 (min, max) 區間的函式,或 None 以隱藏誤差條。請參閱誤差條教學以獲取更多資訊。
在 v0.12.0 版本中新增。
- n_boot整數
用於計算信賴區間的引導樣本數。
- seed整數、
numpy.random.Generator或numpy.random.RandomState 用於可重複引導的種子或亂數產生器。
- units
data中的變數名稱或向量資料 抽樣單位的識別碼;由誤差條函式使用,以執行多層引導並考慮重複測量
- weights
data中的變數名稱或向量資料 用於計算加權統計的資料值或資料行。請注意,使用權重可能會限制其他統計選項。
在 v0.13.1 版本中新增。
- colormatplotlib 顏色
繪圖中元素的單一顏色。
- palette調色盤名稱、列表或字典
用於
hue變數不同層級的顏色。應該是可以使用color_palette()解釋的內容,或將色調級別對應到 matplotlib 顏色的字典。- markers字串或字串列表
用於每個
hue級別的標記。- linestyles字串或字串列表
用於每個
hue級別的線條樣式。- dodge布林值或浮點數
沿著類別軸分隔
hue變數每個級別的點的量。設定為True將會套用一個小的預設值。- log_scale布林值或數字,或布林值或數字的配對
將軸刻度設定為對數。單一值會為繪圖中任何數值軸設定資料軸。一對值會獨立設定每個軸。數值會被解釋為所需的基數(預設值為 10)。當為
None或False時,seaborn 會延遲使用現有的軸刻度。在 v0.13.0 版本中新增。
- native_scale布林值
如果為 True,則類別軸上的數值或日期時間值將保持其原始比例,而不是轉換為固定索引。
在 v0.13.0 版本中新增。
- orient“v” | “h” | “x” | “y”
繪圖方向(垂直或水平)。這通常根據輸入變數的類型推斷出來,但當
x和y都是數值或在繪製寬格式資料時,可以用來解決歧義。在版本 v0.13.0 中變更:新增 ‘x’/’y’ 選項,等同於 ‘v’/’h’。
- capsizefloat
誤差線「帽簷」的寬度,相對於長條間距。
- formattercallable
將類別資料轉換為字串的函數。影響分組和刻度標籤。
在 v0.13.0 版本中新增。
- legend“auto”, “brief”, “full”, 或 False
如何繪製圖例。如果為 “brief”,數值
hue和size變數將以均勻間隔的值樣本表示。如果為 “full”,每個群組都會在圖例中獲得一個條目。如果為 “auto”,則根據級別數量選擇簡短或完整表示。如果為False,則不會添加圖例資料且不會繪製圖例。在 v0.13.0 版本中新增。
- err_kwsdict
matplotlib.lines.Line2D的參數,用於誤差線繪圖器。在 v0.13.0 版本中新增。
- cifloat
要顯示的信賴區間級別,範圍為 [0, 100]。
自版本 v0.12.0 起已棄用:請使用
errorbar=("ci", ...)。- errwidthfloat
誤差線條(和帽簷)的粗細,以點為單位。
自版本 0.13.0 起已棄用:請使用
err_kws={'linewidth': ...}。- joinbool
如果為
True,則將點估計值以線條連接。自版本 v0.13.0 起已棄用:設定
linestyle="none"以移除點之間的線條。- scalefloat
繪圖元素的縮放係數。
自版本 v0.13.0 起已棄用:使用
matplotlib.lines.Line2D參數控制元素大小。- axmatplotlib Axes
要將繪圖繪製在其上的 Axes 物件,否則使用目前的 Axes。
- kwargs鍵,值對應
其他參數會傳遞至
matplotlib.lines.Line2D。在 v0.13.0 版本中新增。
- 回傳:
- axmatplotlib Axes
回傳繪製了圖形的 Axes 物件。
注意事項
重要的是要記住,點圖僅顯示平均值(或其他估計值),但在許多情況下,顯示類別變數每個級別的值分佈可能更具參考價值。在這種情況下,其他方法(如箱形圖或小提琴圖)可能更適合。
範例
依類別變數分組並繪製聚合值,附帶信賴區間
sns.pointplot(data=penguins, x="island", y="body_mass_g")
新增第二層分組並用顏色區分
sns.pointplot(data=penguins, x="island", y="body_mass_g", hue="sex")
使用標記和線條樣式冗餘編碼
hue變數,以提高可訪問性sns.pointplot( data=penguins, x="island", y="body_mass_g", hue="sex", markers=["o", "s"], linestyles=["-", "--"], )
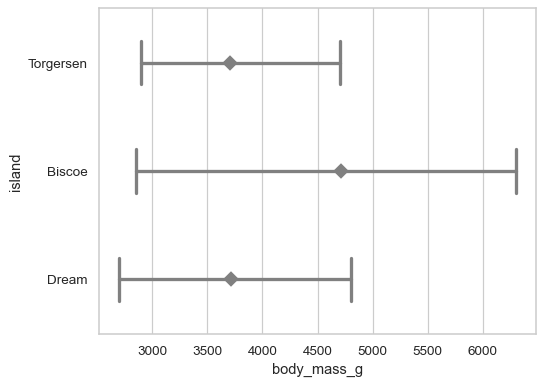
使用誤差線表示每個分佈的標準差
sns.pointplot(data=penguins, x="island", y="body_mass_g", errorbar="sd")
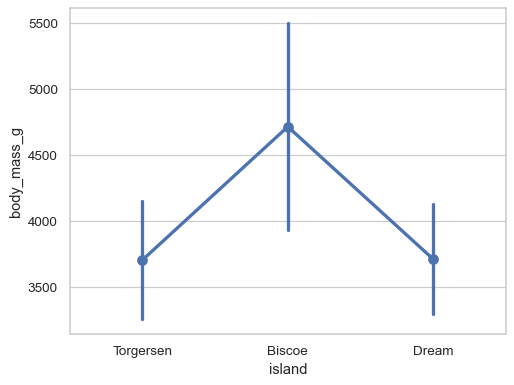
自訂繪圖的外觀
sns.pointplot( data=penguins, x="body_mass_g", y="island", errorbar=("pi", 100), capsize=.4, color=".5", linestyle="none", marker="D", )
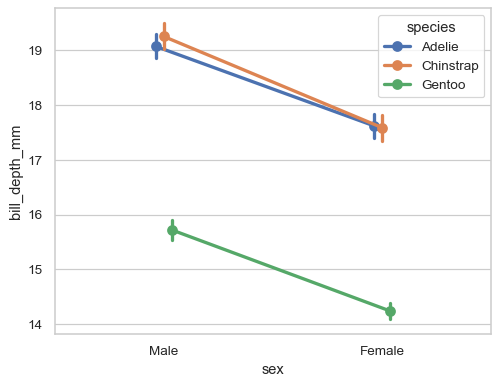
沿著類別軸「閃避」繪圖器,以減少重疊繪圖
sns.pointplot(data=penguins, x="sex", y="bill_depth_mm", hue="species", dodge=True)
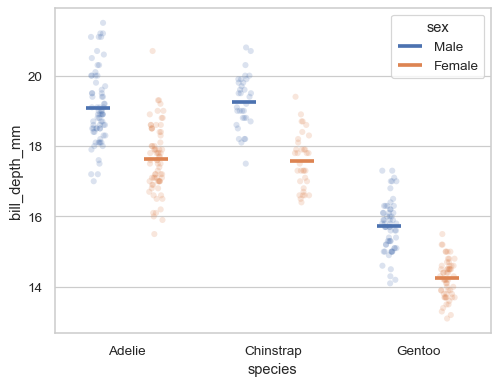
相對於為每個級別分配的寬度,閃避特定量
sns.stripplot( data=penguins, x="species", y="bill_depth_mm", hue="sex", dodge=True, alpha=.2, legend=False, ) sns.pointplot( data=penguins, x="species", y="bill_depth_mm", hue="sex", dodge=.4, linestyle="none", errorbar=None, marker="_", markersize=20, markeredgewidth=3, )
當未明確分配變數且資料集為二維時,繪圖將匯總每列
flights_wide = flights.pivot(index="year", columns="month", values="passengers") sns.pointplot(flights_wide)
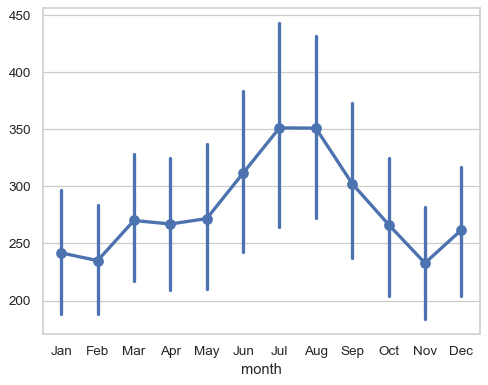
使用一維資料時,會繪製每個值(相對於其鍵或索引,如果可用)
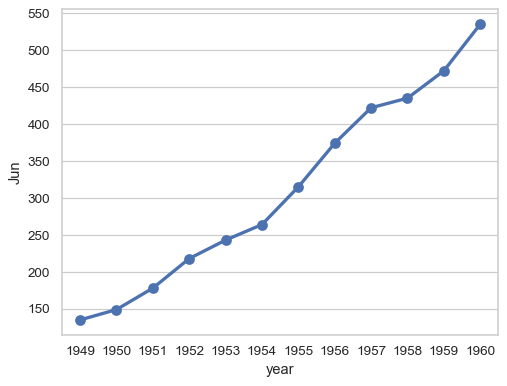
sns.pointplot(flights_wide["Jun"])
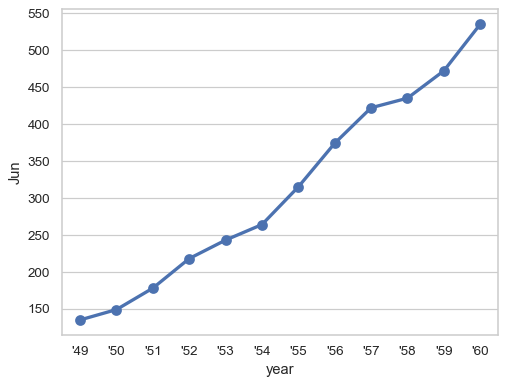
控制類別變數在刻度標籤中顯示的格式
sns.pointplot(flights_wide["Jun"], formatter=lambda x: f"'{x % 1900}")
或保留分組變數的原始比例
ax = sns.pointplot(flights_wide["Jun"], native_scale=True) ax.plot(1955, 335, marker="*", color="r", markersize=10)