seaborn.lineplot#
- seaborn.lineplot(data=None, *, x=None, y=None, hue=None, size=None, style=None, units=None, weights=None, palette=None, hue_order=None, hue_norm=None, sizes=None, size_order=None, size_norm=None, dashes=True, markers=None, style_order=None, estimator='mean', errorbar=('ci', 95), n_boot=1000, seed=None, orient='x', sort=True, err_style='band', err_kws=None, legend='auto', ci='deprecated', ax=None, **kwargs)#
繪製線圖,並具有多個語義分組的可能性。
可以使用
hue、size和style參數,針對資料的不同子集顯示x和y之間的關係。這些參數控制用於識別不同子集的視覺語義。可以使用所有三種語義類型獨立顯示最多三個維度,但這種繪圖風格可能難以解釋,而且通常效果不佳。使用冗餘語義(即對同一個變數同時使用hue和style)有助於使圖形更容易理解。請參閱教學以取得更多資訊。
如果存在,
hue(以及較小程度上的size)語義的預設處理方式取決於推斷變數是否代表「數值」或「類別」資料。特別是,數值變數預設會以循序色圖表示,並且圖例項目會顯示可能存在於資料中或不存在於資料中的規則「刻度」和值。此行為可以透過各種參數控制,如下所述和說明。預設情況下,繪圖會聚合
x的每個值上的多個y值,並顯示中心趨勢的估計值以及該估計值的信賴區間。- 參數:
- data
pandas.DataFrame,numpy.ndarray、映射或序列 輸入資料結構。可以是長格式的向量集合(可以指定給具名變數),或是將在內部重塑的寬格式資料集。
- x、y向量或
data中的鍵 指定 x 和 y 軸位置的變數。
- hue向量或
data中的鍵 分組變數,將產生不同顏色的線條。可以是類別型或數值型,儘管在後者情況下,顏色映射的行為會有所不同。
- size向量或
data中的鍵 分組變數,將產生不同寬度的線條。可以是類別型或數值型,儘管在後者情況下,大小映射的行為會有所不同。
- style向量或
data中的鍵 分組變數,將產生具有不同虛線和/或標記的線條。可以具有數值型 dtype,但始終會被視為類別型。
- units向量或
data中的鍵 識別抽樣單位的分組變數。使用時,將為每個單位繪製一條單獨的線條,並具有適當的語義,但不會新增圖例條目。當不需要確切的身份時,用於顯示實驗重複的分佈很有用。
- weights向量或
data中的鍵 用於計算加權估計的資料值或列。請注意,目前使用權重會將統計量的選擇限制為「平均值」估計器和「ci」誤差條。
- palette字串、列表、字典或
matplotlib.colors.Colormap 用於在映射
hue語義時選擇顏色的方法。字串值會傳遞給color_palette()。列表或字典值表示類別映射,而色彩映射物件表示數值映射。- hue_order字串向量
指定
hue語義的類別級別的處理和繪圖順序。- hue_norm元組或
matplotlib.colors.Normalize 一對在資料單位中設定正規化範圍的值,或一個將資料單位映射到 [0, 1] 區間的物件。使用表示數值映射。
- sizes列表、字典或元組
一個物件,用於決定當使用
size時如何選擇大小。列表或字典引數應為每個唯一的資料值提供一個大小,這會強制進行類別解釋。引數也可以是一個最小值、最大值元組。- size_order列表
指定
size變數級別的出現順序,否則它們將從資料中確定。當size變數為數值時,不相關。- size_norm元組或 Normalize 物件
當
size變數為數值時,用於縮放繪圖物件的資料單位正規化。- dashes布林值、列表或字典
決定如何為
style變數的不同級別繪製線條的物件。設定為True將使用預設的虛線程式碼,或者您可以傳遞虛線程式碼列表或將style變數的級別映射到虛線程式碼的字典。設定為False將對所有子集使用實線。虛線指定方式與 matplotlib 中相同:(線段, 間隙)長度的元組,或為空字串以繪製實線。- markers布林值、列表或字典
決定如何為
style變數的不同級別繪製標記的物件。設定為True將使用預設標記,或者您可以傳遞標記列表或將style變數的級別映射到標記的字典。設定為False將繪製無標記的線條。標記的指定方式與 matplotlib 中相同。- style_order列表
指定
style變數級別的出現順序,否則它們將從資料中確定。當style變數為數值時,不相關。- estimatorpandas 方法或可呼叫物件的名稱,或 None
用於在同一
x級別上聚合y變數的多個觀測值的方法。如果為None,則將繪製所有觀測值。- errorbar字串、(字串、數字) 元組或可呼叫物件
誤差條方法的名稱(「ci」、「pi」、「se」或「sd」),或包含方法名稱和層級參數的元組,或從向量映射到 (最小值、最大值) 區間的函數,或 None 以隱藏誤差條。請參閱 誤差條教學課程 以取得更多資訊。
- n_boot整數
用於計算信賴區間的自助法數量。
- seed整數、numpy.random.Generator 或 numpy.random.RandomState
用於可重複自助法的種子或亂數產生器。
- orient"x" 或 "y"
資料排序/聚合的維度。等效地,結果函數的「獨立變數」。
- sort布林值
如果為 True,則資料將按 x 和 y 變數排序,否則線條將按照它們在資料集中出現的順序連接點。
- err_style"band" 或 "bars"
是否使用半透明誤差帶或離散誤差條繪製信賴區間。
- err_kws關鍵字引數字典
用於控制誤差條美感的其他參數。kwargs 會傳遞給
matplotlib.axes.Axes.fill_between()或matplotlib.axes.Axes.errorbar(),具體取決於err_style。- legend"auto"、"brief"、"full" 或 False
如何繪製圖例。如果為「brief」,則數值
hue和size變數將以均勻間隔的值的樣本表示。如果為「full」,則每個群組都會在圖例中取得一個條目。如果為「auto」,則根據級別數量在簡短或完整表示之間選擇。如果為False,則不會新增圖例資料,也不會繪製圖例。- ci整數或 "sd" 或 None
在聚合時繪製的信賴區間大小。
自版本 0.12.0 起已棄用:請使用新的
errorbar參數以獲得更高的彈性。- ax
matplotlib.axes.Axes 繪圖的預先存在的軸。否則,在內部呼叫
matplotlib.pyplot.gca()。- kwargs鍵值對映
其他關鍵字引數會向下傳遞給
matplotlib.axes.Axes.plot()。
- data
- 傳回值:
matplotlib.axes.Axes包含繪圖的 matplotlib 軸。
另請參閱
scatterplot使用點繪製資料。
pointplot使用標記和線條繪製點估計和 CI。
範例
flights資料集具有 10 年的每月航空公司乘客資料flights = sns.load_dataset("flights") flights.head()
year month passengers 0 1949 Jan 112 1 1949 Feb 118 2 1949 Mar 132 3 1949 Apr 129 4 1949 May 121 若要使用長格式資料繪製折線圖,請指定
x和y變數may_flights = flights.query("month == 'May'") sns.lineplot(data=may_flights, x="year", y="passengers")
將資料框架樞紐轉換為寬格式表示法
flights_wide = flights.pivot(index="year", columns="month", values="passengers") flights_wide.head()
month Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec year 1949 112 118 132 129 121 135 148 148 136 119 104 118 1950 115 126 141 135 125 149 170 170 158 133 114 140 1951 145 150 178 163 172 178 199 199 184 162 146 166 1952 171 180 193 181 183 218 230 242 209 191 172 194 1953 196 196 236 235 229 243 264 272 237 211 180 201 若要繪製單個向量,請將其傳遞給
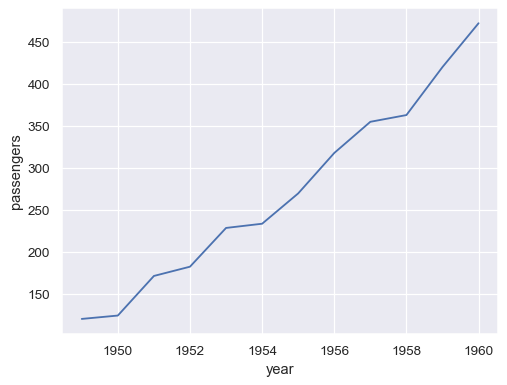
data。如果向量是pandas.Series,則將根據其索引繪製sns.lineplot(data=flights_wide["May"])
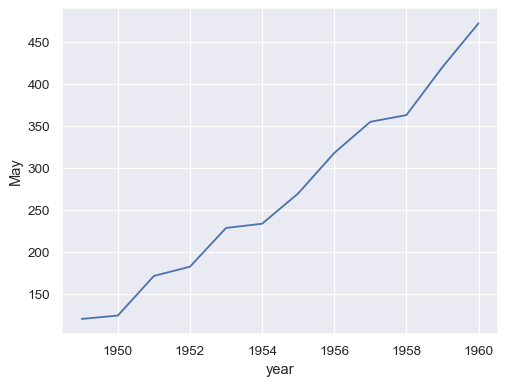
將整個寬格式資料集傳遞給
data會為每一列繪製一條單獨的線條sns.lineplot(data=flights_wide)
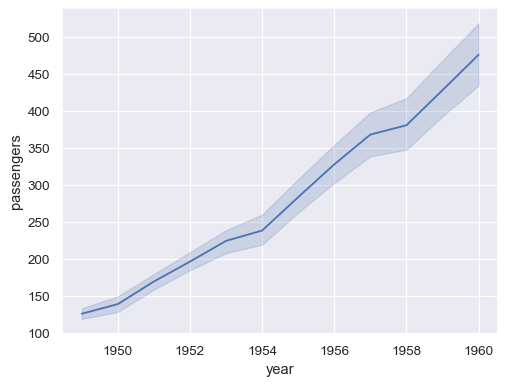
以長格式模式傳遞整個資料集將聚合重複值(每年)以顯示平均值和 95% 信賴區間
sns.lineplot(data=flights, x="year", y="passengers")
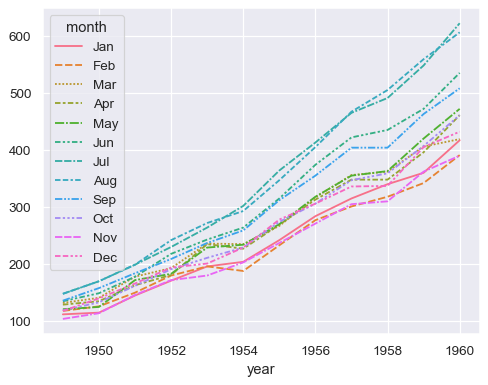
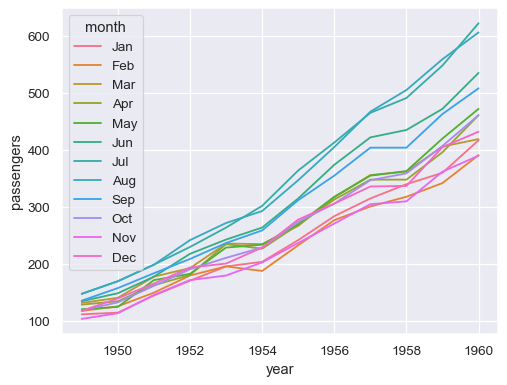
指派分組語義 (
hue、size或style) 以繪製單獨的線條sns.lineplot(data=flights, x="year", y="passengers", hue="month")
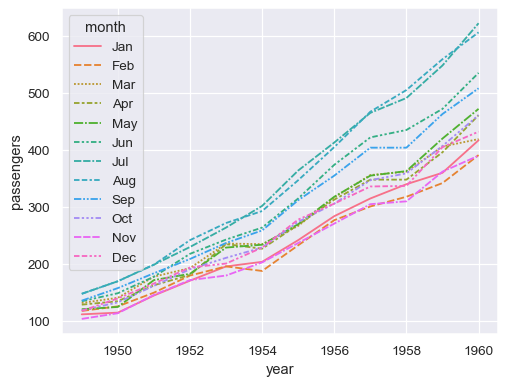
可以將相同的列指派給多個語義變數,這可以提高繪圖的可存取性
sns.lineplot(data=flights, x="year", y="passengers", hue="month", style="month")
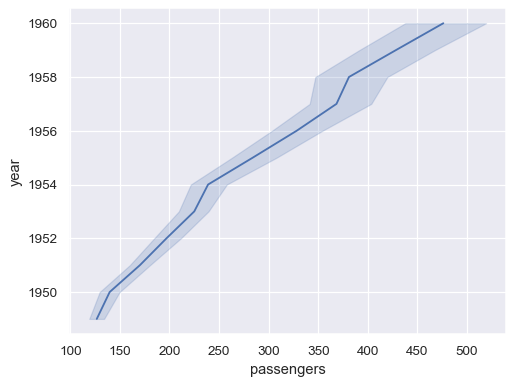
使用
orient參數以沿繪圖的垂直維度聚合和排序sns.lineplot(data=flights, x="passengers", y="year", orient="y")
每個語義變數也可以表示不同的列。為此,我們需要一個更複雜的資料集
fmri = sns.load_dataset("fmri") fmri.head()
subject timepoint event region signal 0 s13 18 stim parietal -0.017552 1 s5 14 stim parietal -0.080883 2 s12 18 stim parietal -0.081033 3 s11 18 stim parietal -0.046134 4 s10 18 stim parietal -0.037970 即使使用語義分組,也會聚合重複的觀測值
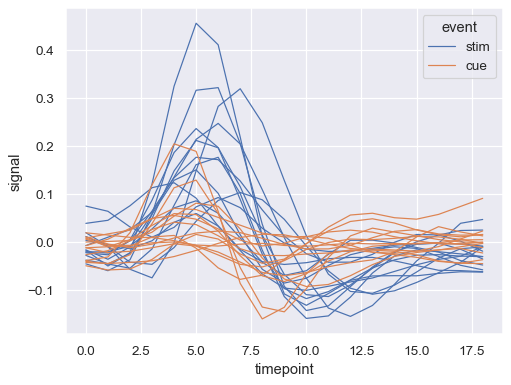
sns.lineplot(data=fmri, x="timepoint", y="signal", hue="event")
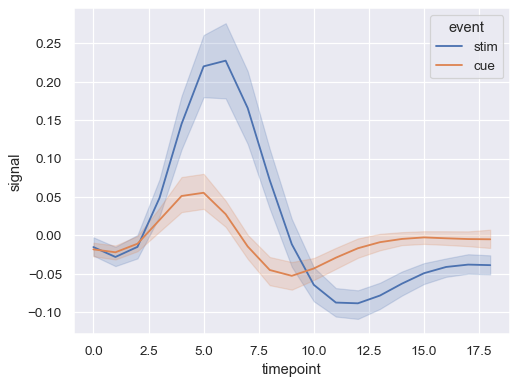
同時指派
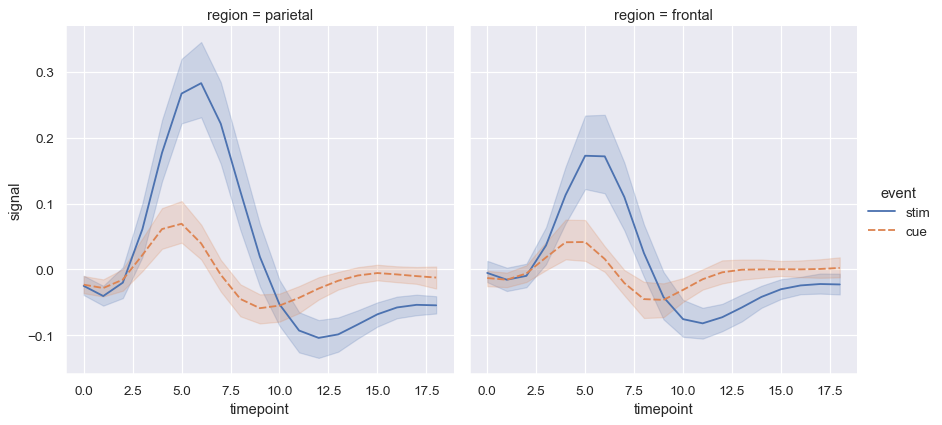
hue和style以表示兩個不同的分組變數sns.lineplot(data=fmri, x="timepoint", y="signal", hue="region", style="event")
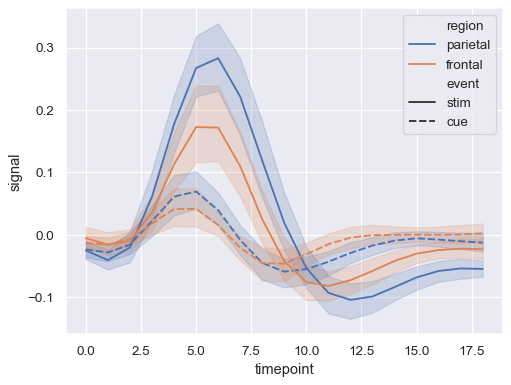
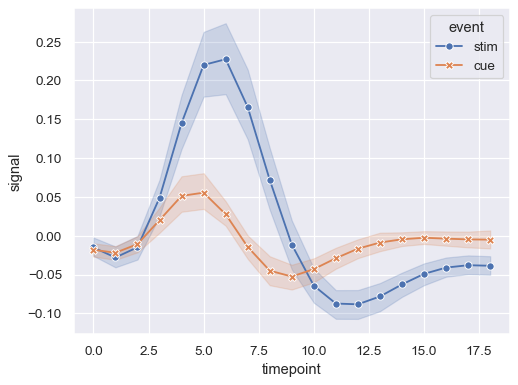
在指派
style變數時,可以使用標記來代替(或同時使用)虛線來區分群組sns.lineplot( data=fmri, x="timepoint", y="signal", hue="event", style="event", markers=True, dashes=False )
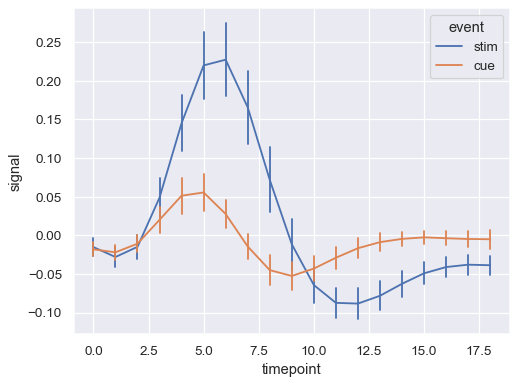
顯示誤差條而不是誤差帶,並將它們擴展到兩個標準誤差寬度
sns.lineplot( data=fmri, x="timepoint", y="signal", hue="event", err_style="bars", errorbar=("se", 2), )
指派
units變數將繪製多條線條,而無需套用語義映射sns.lineplot( data=fmri.query("region == 'frontal'"), x="timepoint", y="signal", hue="event", units="subject", estimator=None, lw=1, )
載入另一個具有數值分組變數的資料集
dots = sns.load_dataset("dots").query("align == 'dots'") dots.head()
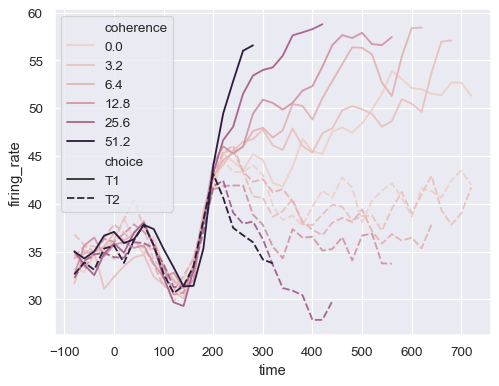
align choice time coherence firing_rate 0 dots T1 -80 0.0 33.189967 1 dots T1 -80 3.2 31.691726 2 dots T1 -80 6.4 34.279840 3 dots T1 -80 12.8 32.631874 4 dots T1 -80 25.6 35.060487 將數值變數指派給
hue會以不同的方式對其進行映射,使用不同的預設調色盤和定量色彩映射sns.lineplot( data=dots, x="time", y="firing_rate", hue="coherence", style="choice", )
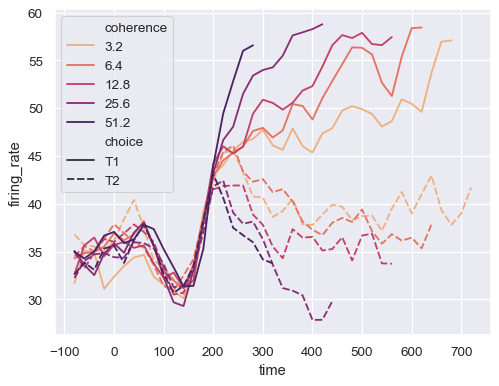
透過設定
palette並傳遞matplotlib.colors.Normalize物件來控制色彩映射sns.lineplot( data=dots.query("coherence > 0"), x="time", y="firing_rate", hue="coherence", style="choice", palette="flare", hue_norm=mpl.colors.LogNorm(), )
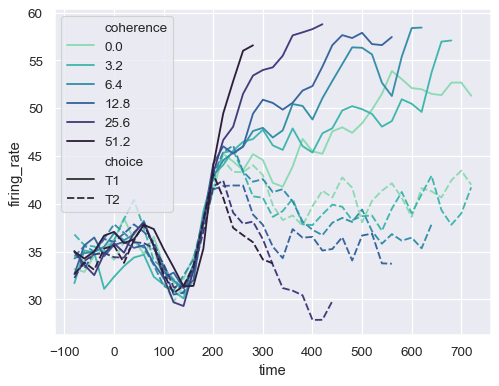
或者傳遞特定的顏色,可以使用 Python 列表或字典的形式。
palette = sns.color_palette("mako_r", 6) sns.lineplot( data=dots, x="time", y="firing_rate", hue="coherence", style="choice", palette=palette )
將
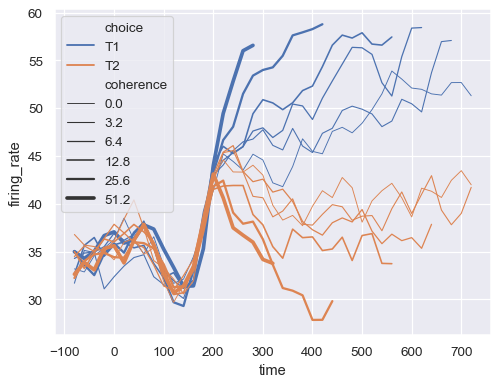
size語義指定為對應數值變數的線條寬度。sns.lineplot( data=dots, x="time", y="firing_rate", size="coherence", hue="choice", legend="full" )
傳遞一個元組,
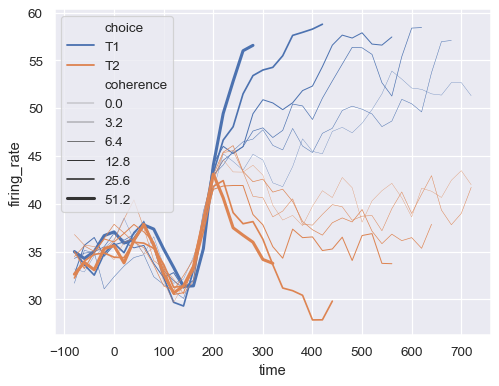
sizes=(最小寬度, 最大寬度),來控制用於對應size語義的線寬範圍。sns.lineplot( data=dots, x="time", y="firing_rate", size="coherence", hue="choice", sizes=(.25, 2.5) )
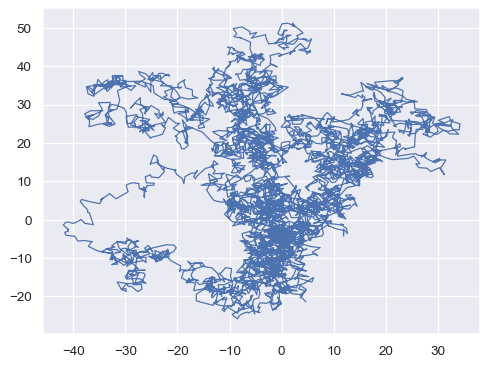
預設情況下,觀察值會按照
x排序。停用此設定以按照觀察值在數據集中出現的順序繪製線條。x, y = np.random.normal(size=(2, 5000)).cumsum(axis=1) sns.lineplot(x=x, y=y, sort=False, lw=1)
使用
relplot()來結合lineplot()和FacetGrid。這允許在其他類別變數中進行分組。使用relplot()比直接使用FacetGrid更安全,因為它可以確保各個分面之間語義映射的同步。sns.relplot( data=fmri, x="timepoint", y="signal", col="region", hue="event", style="event", kind="line" )