seaborn.histplot#
- seaborn.histplot(data=None, *, x=None, y=None, hue=None, weights=None, stat='count', bins='auto', binwidth=None, binrange=None, discrete=None, cumulative=False, common_bins=True, common_norm=True, multiple='layer', element='bars', fill=True, shrink=1, kde=False, kde_kws=None, line_kws=None, thresh=0, pthresh=None, pmax=None, cbar=False, cbar_ax=None, cbar_kws=None, palette=None, hue_order=None, hue_norm=None, color=None, log_scale=None, legend=True, ax=None, **kwargs)#
繪製單變數或雙變數直方圖,以顯示資料集的分布。
直方圖是一種經典的視覺化工具,它通過計算落在離散區間(bin)內的觀測次數來表示一個或多個變數的分布。
此函數可以將每個區間內計算的統計量正規化,以估計頻率、密度或機率質量,並且可以添加使用核密度估計獲得的平滑曲線,類似於
kdeplot()。更多資訊請參閱使用者指南。
- 參數:
- data
pandas.DataFrame、numpy.ndarray、映射或序列 輸入資料結構。可以是可指定給命名變數的長格式向量集合,也可以是將在內部重新塑形的寬格式資料集。
- x, y向量或
data中的鍵 指定 x 軸和 y 軸位置的變數。
- hue向量或
data中的鍵 映射以確定繪圖元素顏色的語義變數。
- weights向量或
data中的鍵 如果提供,則將相應資料點對每個區間計數的貢獻,按這些因素加權。
- statstr
在每個區間中計算的聚合統計量。
count: 顯示每個區間中的觀測次數frequency: 顯示觀測次數除以區間寬度probability或proportion: 正規化,使長條圖高度總和為 1percent: 正規化,使長條圖高度總和為 100density: 正規化,使直方圖總面積等於 1
- binsstr、數字、向量或此類值的配對
一般區間參數,可以是參考規則的名稱、區間數或區間的中斷點。傳遞至
numpy.histogram_bin_edges()。- binwidth數字或數字配對
每個區間的寬度,會覆寫
bins,但可與binrange一起使用。- binrange數字配對或配對的配對
區間邊緣的最低值和最高值;可與
bins或binwidth一起使用。預設為資料極值。- discretebool
如果為 True,則預設為
binwidth=1,並繪製長條圖,使其在對應的資料點上居中。這可以避免在使用離散(整數)資料時可能出現的「間隙」。- cumulativebool
如果為 True,則隨著區間增加,繪製累積計數。
- common_binsbool
如果為 True,當語義變數產生多個圖表時,會使用相同的 bin。如果使用參考規則來決定 bin,則將使用完整資料集進行計算。
- common_normbool
如果為 True 且使用標準化統計數據,則標準化將應用於完整資料集。否則,將獨立標準化每個直方圖。
- multiple{“layer”, “dodge”, “stack”, “fill”}
當語義映射建立子集時,解決多個元素的方法。僅適用於單變量資料。
- element{“bars”, “step”, “poly”}
直方圖統計數據的視覺表示。僅適用於單變量資料。
- fillbool
如果為 True,則填充直方圖下的空間。僅適用於單變量資料。
- shrinknumber
相對於 binwidth,以此因子縮放每個條形的寬度。僅適用於單變量資料。
- kdebool
如果為 True,則計算核密度估計以平滑分佈,並在圖表上顯示為(一個或多個)線條。僅適用於單變量資料。
- kde_kwsdict
控制 KDE 計算的參數,如同
kdeplot()。- line_kwsdict
控制 KDE 可視化的參數,傳遞給
matplotlib.axes.Axes.plot()。- threshnumber 或 None
統計數據小於或等於此值的儲存格將為透明。僅適用於雙變量資料。
- pthreshnumber 或 None
與
thresh類似,但值在 [0, 1] 之間,使得累計計數(或使用時的其他統計數據)達到總數此比例的儲存格將為透明。- pmaxnumber 或 None
在 [0, 1] 之間的值,用於設置色彩映射的飽和點,使得低於該值的儲存格構成總計數(或使用時的其他統計數據)的此比例。
- cbarbool
如果為 True,則添加色彩條以註解雙變量圖表中的色彩映射。注意:目前不支援具有
hue變數的圖表。- cbar_ax
matplotlib.axes.Axes 色彩條的預先存在的軸。
- cbar_kwsdict
傳遞給
matplotlib.figure.Figure.colorbar()的其他參數。- palettestring, list, dict, 或
matplotlib.colors.Colormap 選擇用於映射
hue語義的顏色的方法。字串值會傳遞給color_palette()。列表或字典值表示類別映射,而色彩映射物件表示數值映射。- hue_order字串向量
指定
hue語義的類別級別的處理和繪圖順序。- hue_norm元組或
matplotlib.colors.Normalize 一對值,用於在資料單位中設定標準化範圍,或將資料單位映射到 [0, 1] 區間的物件。使用表示數值映射。
- color
matplotlib color 當不使用色調映射時的單一顏色規格。否則,繪圖將嘗試掛接到 matplotlib 屬性循環。
- log_scalebool 或數字,或一對 bool 或數字
將軸刻度設定為對數。單一值設定圖表中任何數值軸的資料軸。一對值獨立設定每個軸。數值被解讀為所需的底數(預設為 10)。當
None或False時,seaborn 會延遲到現有的軸刻度。- legendbool
如果為 False,則抑制語義變數的圖例。
- ax
matplotlib.axes.Axes 圖表的預先存在的軸。否則,請在內部呼叫
matplotlib.pyplot.gca()。- kwargs
其他關鍵字引數會傳遞給以下 matplotlib 函數之一
matplotlib.axes.Axes.bar()(單變量,element="bars")matplotlib.axes.Axes.fill_between()(單變量,其他 element,fill=True)matplotlib.axes.Axes.plot()(單變量,其他 element,fill=False)
- data
- 返回:
matplotlib.axes.Axes包含圖表的 matplotlib 軸。
另請參閱
注意事項
用於計算和繪製直方圖的 bin 選擇可能會對從視覺化中獲得的見解產生重大影響。如果 bin 太大,可能會抹除重要的特徵。另一方面,如果 bin 太小,則可能會被隨機變異性主導,從而模糊真實底層分佈的形狀。預設 bin 大小是使用取決於樣本大小和變異數的參考規則來確定的。這在許多情況下(即,對於「行為良好」的資料)都有效,但在其他情況下會失敗。始終最好嘗試不同的 bin 大小,以確保您不會錯過任何重要資訊。此函數允許您以多種不同的方式指定 bin,例如設定要使用的 bin 總數、每個 bin 的寬度或 bin 應分割的特定位置。
範例
將變數指派給
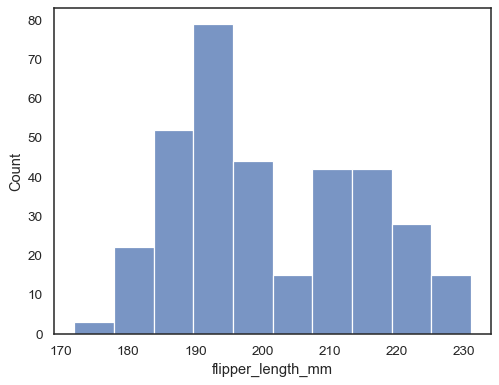
x以沿 x 軸繪製單變量分佈penguins = sns.load_dataset("penguins") sns.histplot(data=penguins, x="flipper_length_mm")
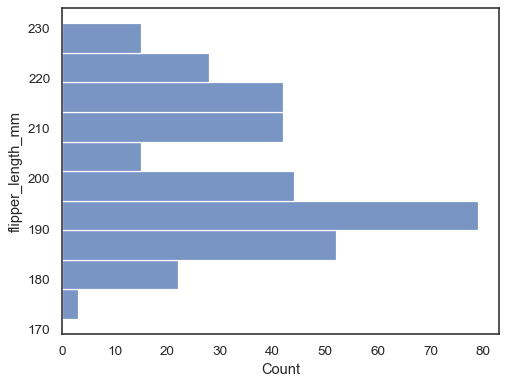
透過將資料變數指派給 y 軸來翻轉圖表
sns.histplot(data=penguins, y="flipper_length_mm")
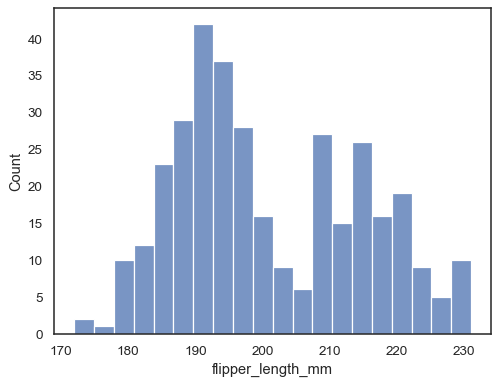
透過指定不同的 bin 寬度來檢查直方圖如何表示資料
sns.histplot(data=penguins, x="flipper_length_mm", binwidth=3)
您也可以定義要使用的 bin 總數
sns.histplot(data=penguins, x="flipper_length_mm", bins=30)
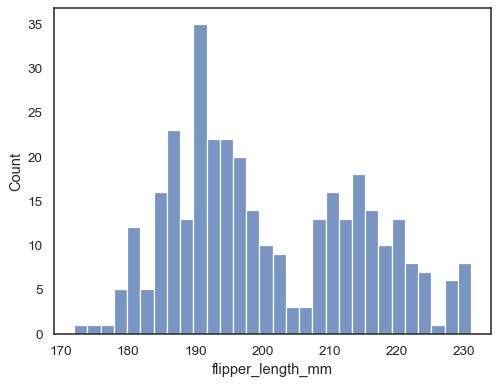
新增核密度估計以平滑直方圖,提供有關分佈形狀的補充資訊
sns.histplot(data=penguins, x="flipper_length_mm", kde=True)
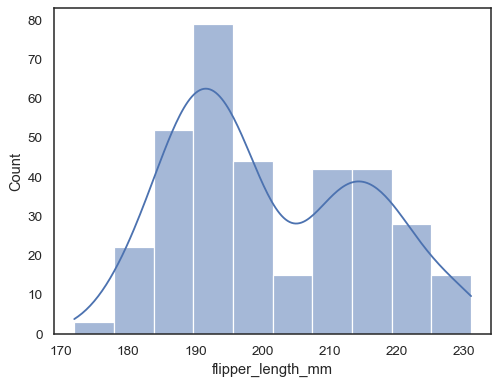
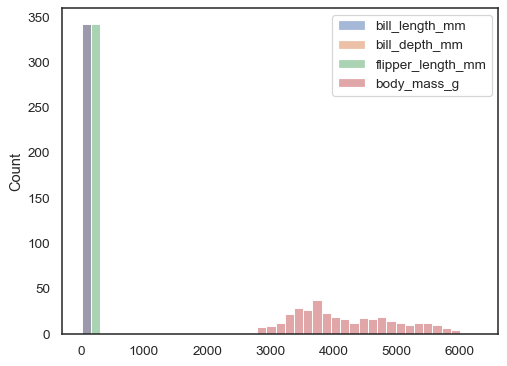
如果未指派
x或y,則資料集會被視為寬格式,並且會為每個數值欄位繪製直方圖sns.histplot(data=penguins)
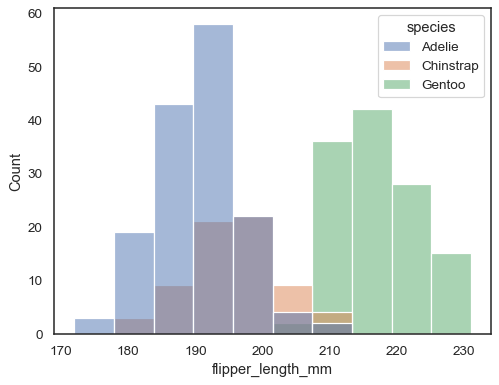
否則,您可以從具有色調映射的長格式資料集中繪製多個直方圖
sns.histplot(data=penguins, x="flipper_length_mm", hue="species")
繪製多個分佈的預設方法是「分層」它們,但您也可以「堆疊」它們
sns.histplot(data=penguins, x="flipper_length_mm", hue="species", multiple="stack")
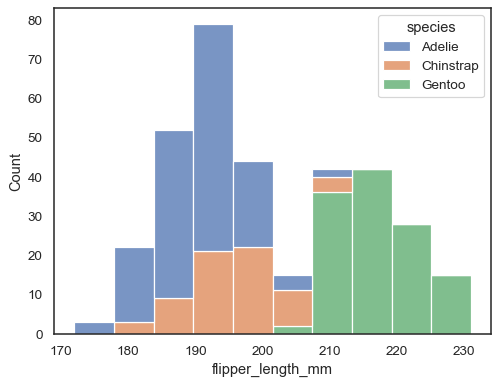
重疊的條形可能難以視覺解析。不同的方法是繪製階躍函數
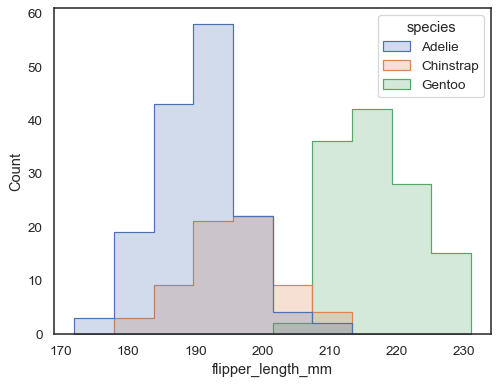
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="step")
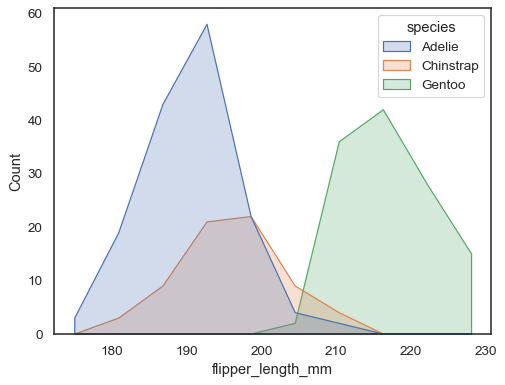
您可以透過在每個 bin 的中心繪製頂點的多邊形來進一步遠離條形。這可能會讓您更容易看到分佈的形狀,但請謹慎使用:您的觀眾將不太清楚他們正在看直方圖
sns.histplot(penguins, x="flipper_length_mm", hue="species", element="poly")
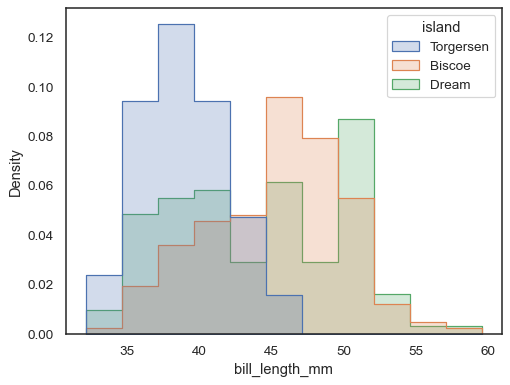
若要比較大小差異很大的子集分佈,請使用獨立的密度標準化
sns.histplot( penguins, x="bill_length_mm", hue="island", element="step", stat="density", common_norm=False, )
也可以標準化,使每個條形的高度顯示機率、比例或百分比,這對於離散變數更有意義
tips = sns.load_dataset("tips") sns.histplot(data=tips, x="size", stat="percent", discrete=True)
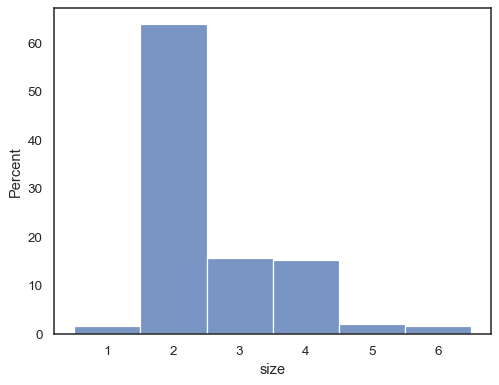
您甚至可以繪製類別變數的直方圖(儘管這是一個實驗性功能)
sns.histplot(data=tips, x="day", shrink=.8)
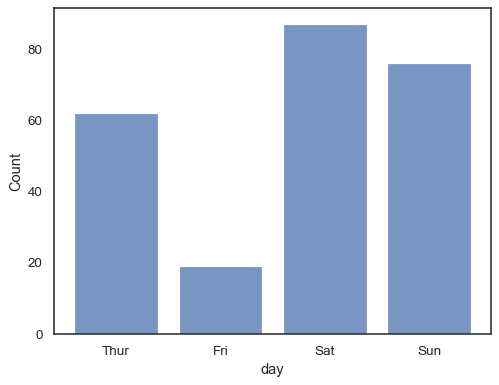
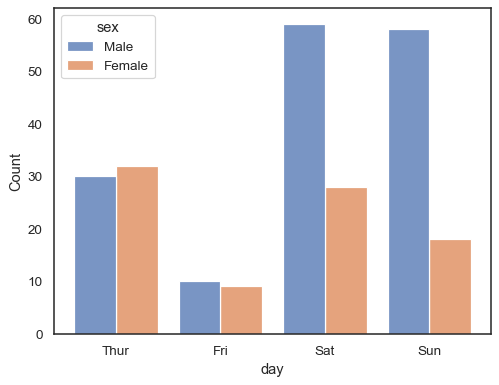
當使用帶有離散數據的
hue語意時,將各層級「錯開」顯示可能較為合理。sns.histplot(data=tips, x="day", hue="sex", multiple="dodge", shrink=.8)
真實世界的數據通常會呈現偏斜。對於嚴重偏斜的分布,最好在對數空間中定義分組。請比較
planets = sns.load_dataset("planets") sns.histplot(data=planets, x="distance")
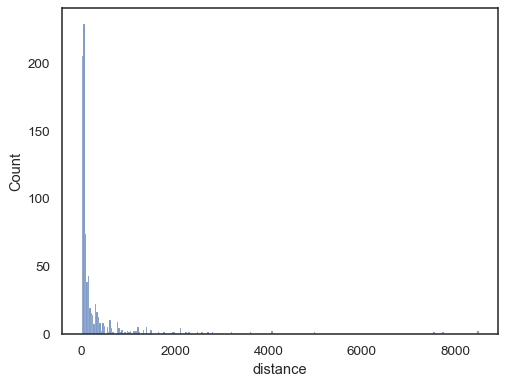
與對數刻度版本的比較
sns.histplot(data=planets, x="distance", log_scale=True)
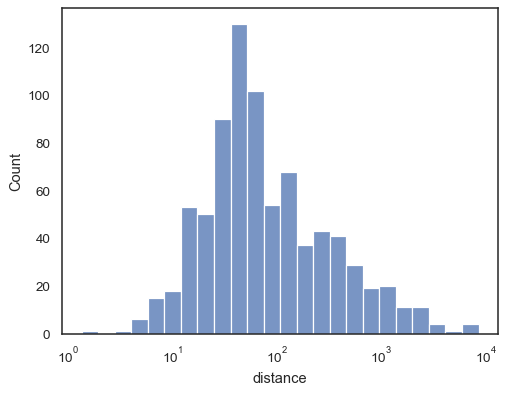
長條圖的呈現方式也有多種選項。您可以顯示未填滿的長條
sns.histplot(data=planets, x="distance", log_scale=True, fill=False)
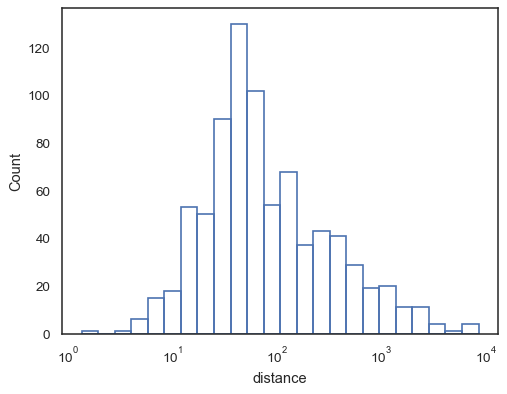
或者未填滿的階梯函數
sns.histplot(data=planets, x="distance", log_scale=True, element="step", fill=False)
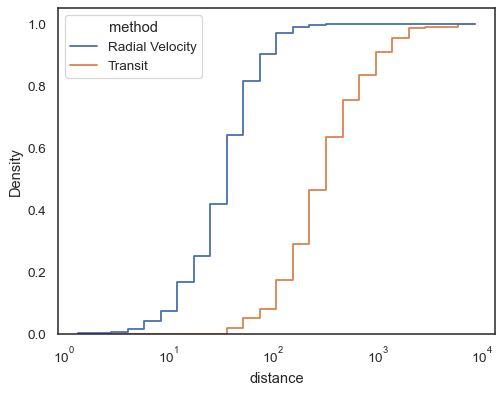
階梯函數,尤其是在未填滿的情況下,可以輕鬆比較累積長條圖
sns.histplot( data=planets, x="distance", hue="method", hue_order=["Radial Velocity", "Transit"], log_scale=True, element="step", fill=False, cumulative=True, stat="density", common_norm=False, )
當同時指定
x和y時,將計算雙變數直方圖並顯示為熱圖sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g")
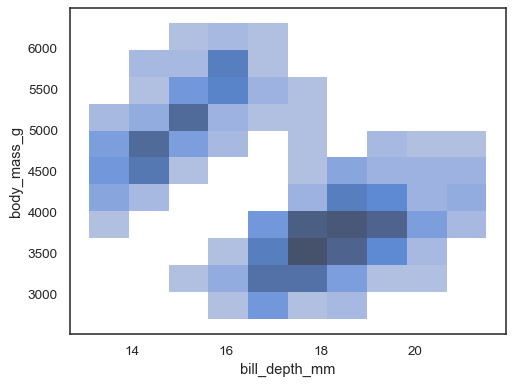
也可以指定
hue變數,但如果來自不同層級的數據有大量重疊,則效果不佳sns.histplot(penguins, x="bill_depth_mm", y="body_mass_g", hue="species")
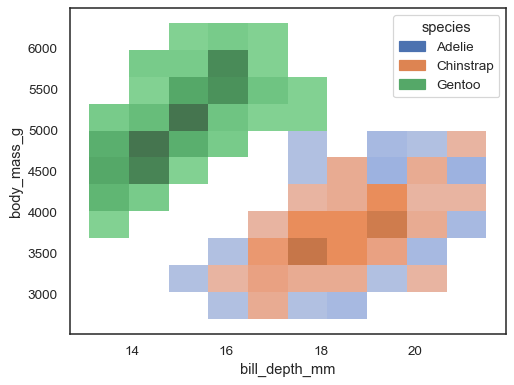
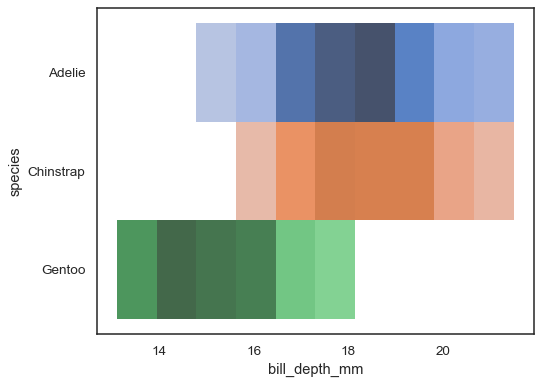
當其中一個變數為離散型時,使用多個顏色地圖可能較為合理
sns.histplot( penguins, x="bill_depth_mm", y="species", hue="species", legend=False )
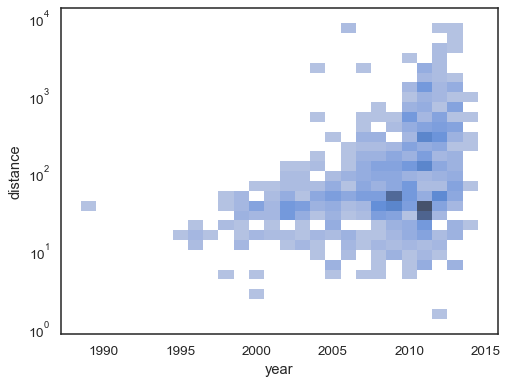
雙變數直方圖接受與單變數直方圖相同的計算選項,使用元組來獨立參數化
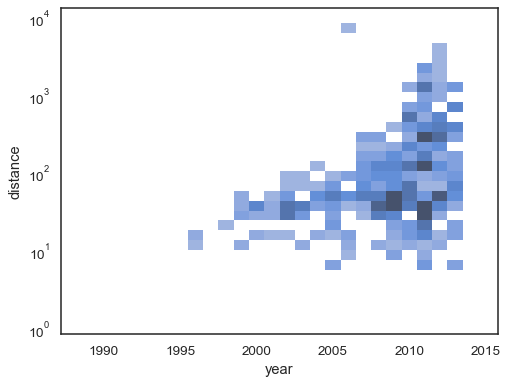
x和ysns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), )
預設行為會使沒有觀測值的儲存格透明,雖然此設定可以停用
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), thresh=None, )
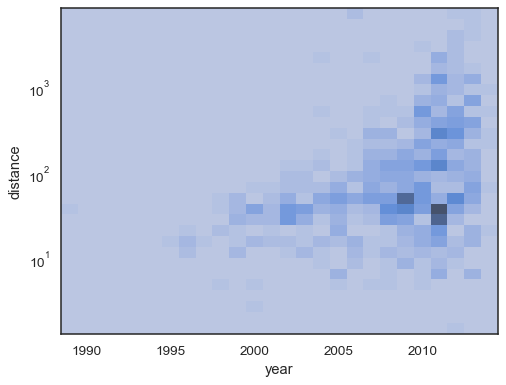
也可以根據累積計數的比例來設定閾值和色彩映射飽和點
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), pthresh=.05, pmax=.9, )
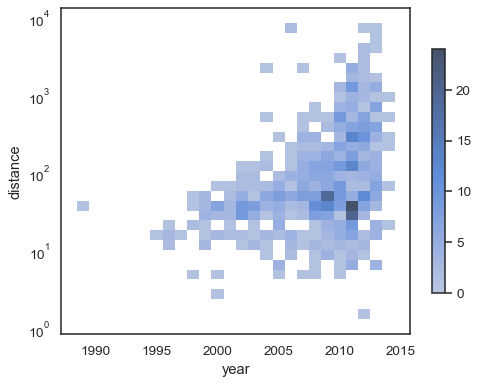
若要註解色彩映射,請加入色條
sns.histplot( planets, x="year", y="distance", bins=30, discrete=(True, False), log_scale=(False, True), cbar=True, cbar_kws=dict(shrink=.75), )