seaborn.objects.Est#
- class seaborn.objects.Est(func='mean', errorbar=('ci', 95), n_boot=1000, seed=None)#
計算點估計值和誤差條區間。
關於各種
errorbar選項的詳細資訊,請參閱誤差條教學。其他變數
weight:當傳遞給使用此統計量的圖層時,將計算加權估計值。 請注意,目前使用權重會將函數和誤差條方法的選擇限制為
"mean"和"ci"。
- 參數:
- func字串或可呼叫物件
numpy.ndarray方法的名稱或向量 → 純量函數。- errorbar字串、(字串、浮點數) 元組或可呼叫物件
誤差條方法的名稱 (「ci」、「pi」、「se」 或 「sd」 其中之一),或是包含方法名稱和層級參數的元組,或是將向量對應至 (最小值、最大值) 區間的函數。
- n_boot整數
為「ci」誤差條繪製的 bootstrap 樣本數。
- seed整數
用於繪製 bootstrap 樣本的 PRNG 的種子。
範例
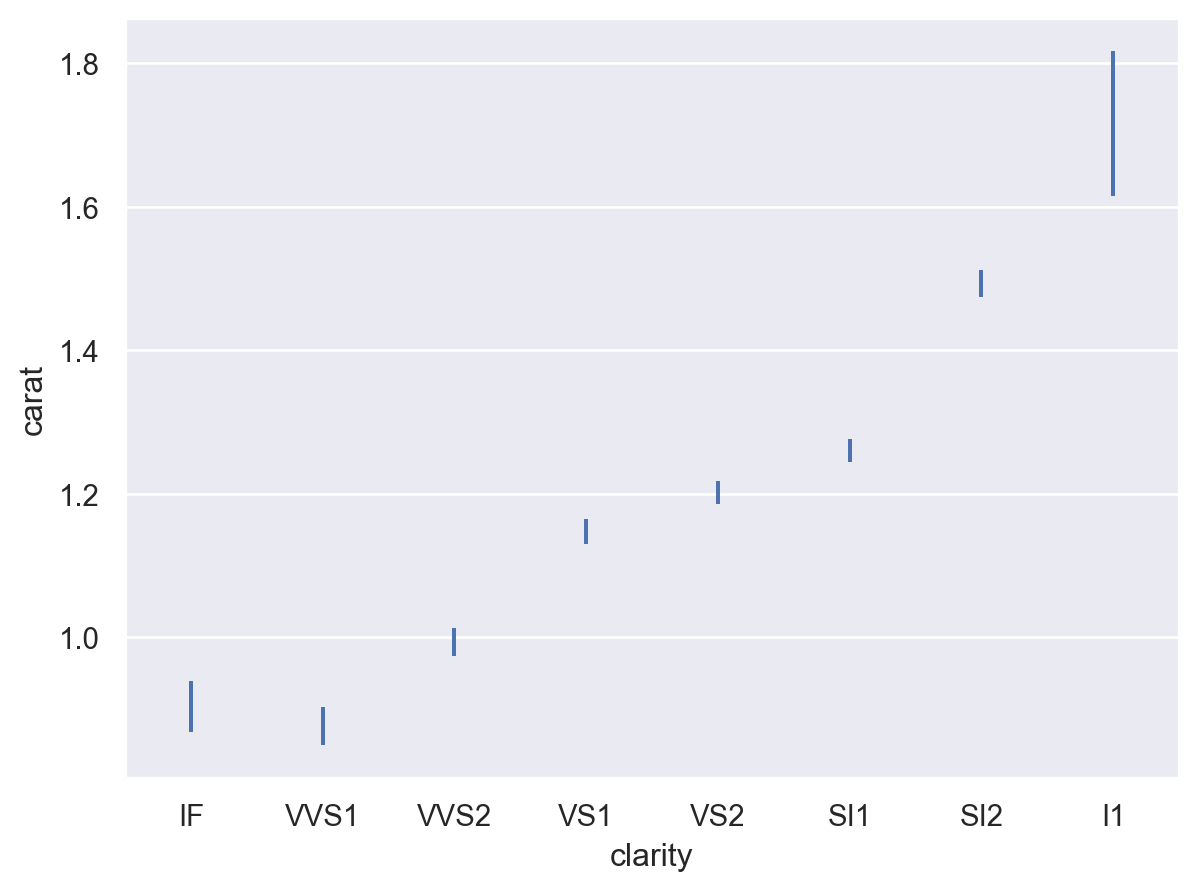
預設行為是計算平均值和 95% 信賴區間 (使用 bootstrapping)
p = so.Plot(diamonds, "clarity", "carat") p.add(so.Range(), so.Est())
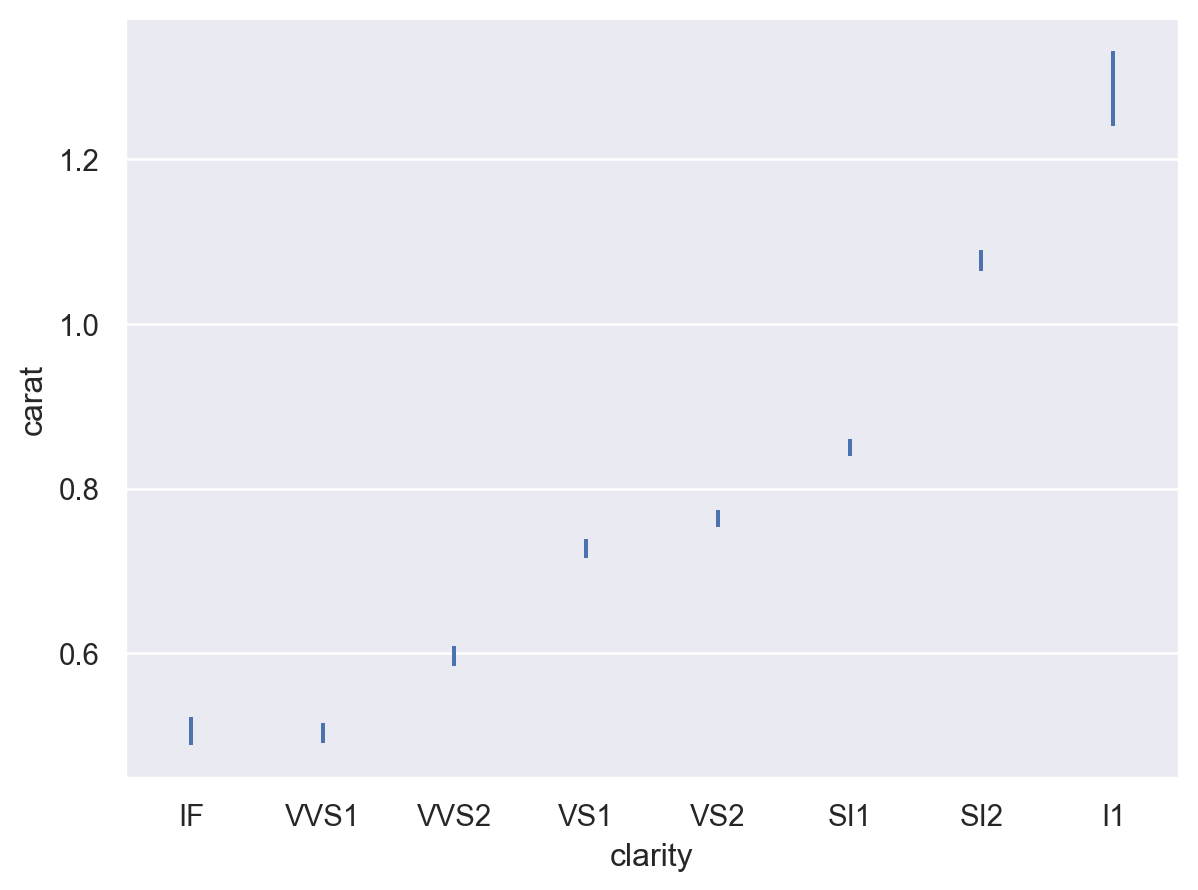
如果其他估計器是 pandas 方法,則可以按名稱選擇
p.add(so.Range(), so.Est("median"))
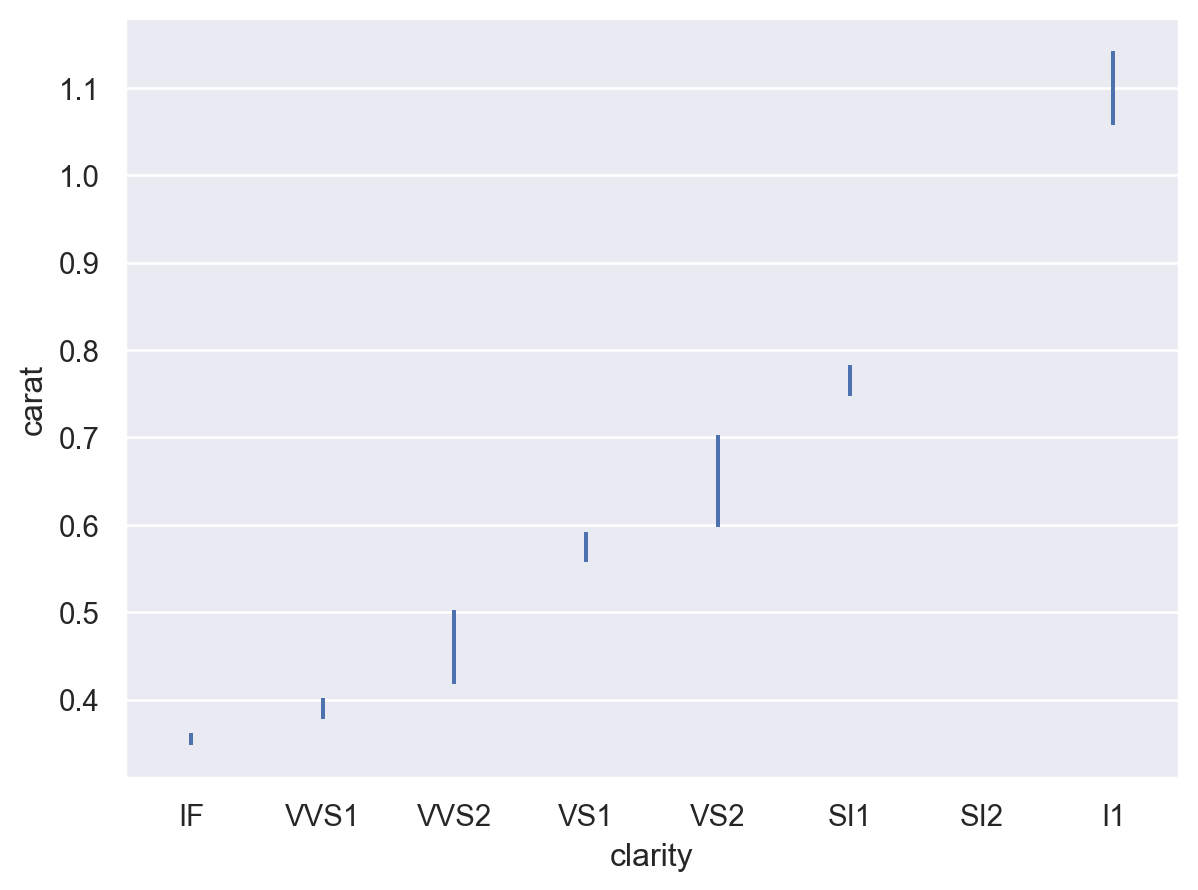
計算誤差條區間有多種選項,例如 (縮放) 標準誤差
p.add(so.Range(), so.Est(errorbar="se"))
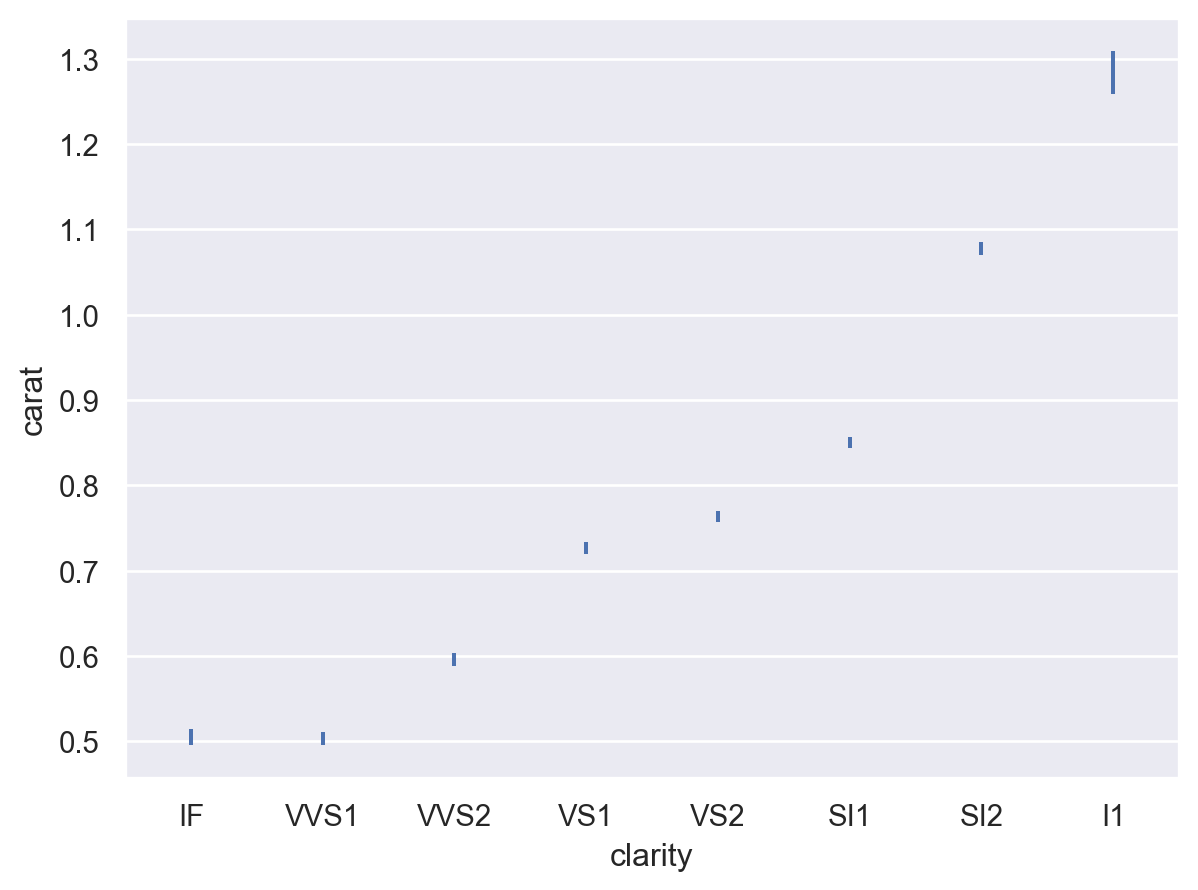
誤差條也可以使用 (縮放) 標準差表示估計值周圍的分佈範圍
p.add(so.Range(), so.Est(errorbar="sd"))
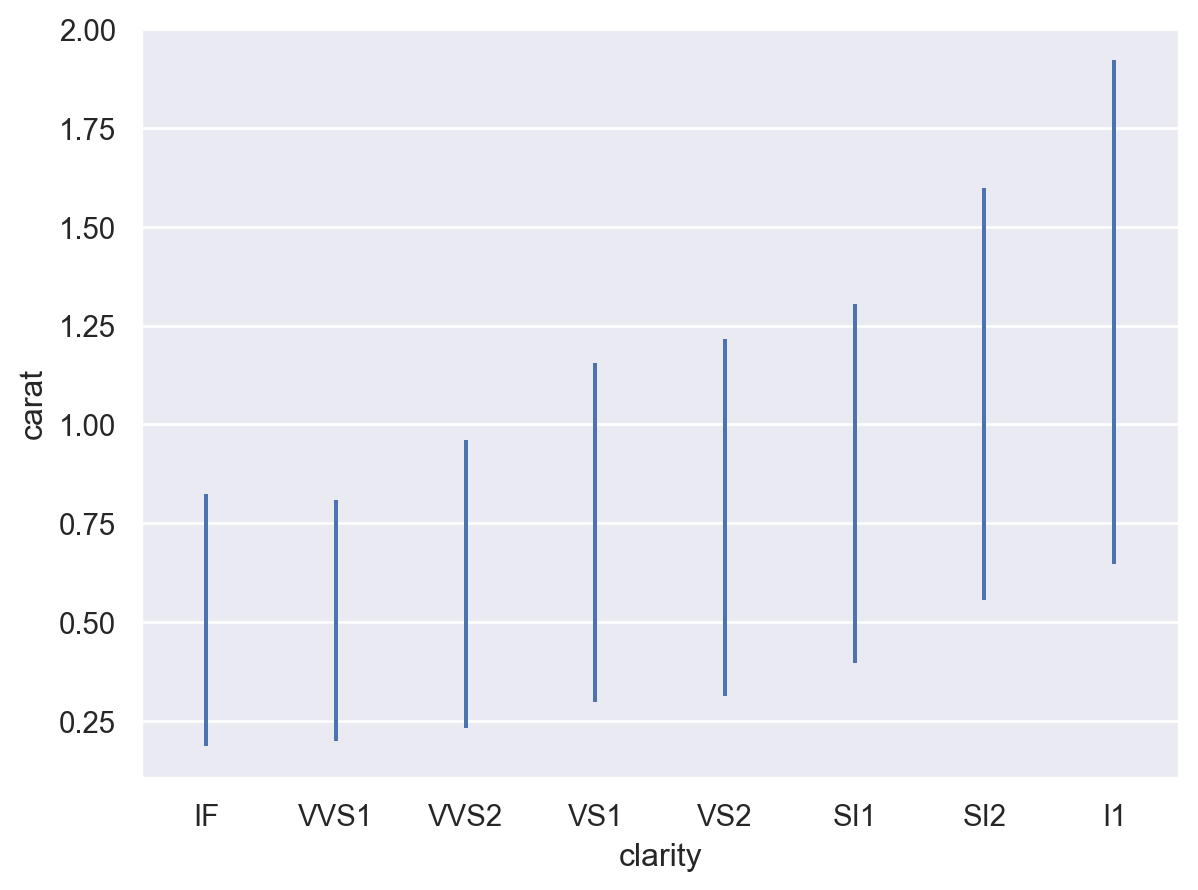
因為信賴區間是使用 bootstrapping 計算的,所以會有少量的隨機性。 增加 bootstrap 迭代次數可以減少隨機變異性 (雖然這樣會較慢),或者可以透過設定亂數產生器的種子來消除。
p.add(so.Range(), so.Est(seed=0))
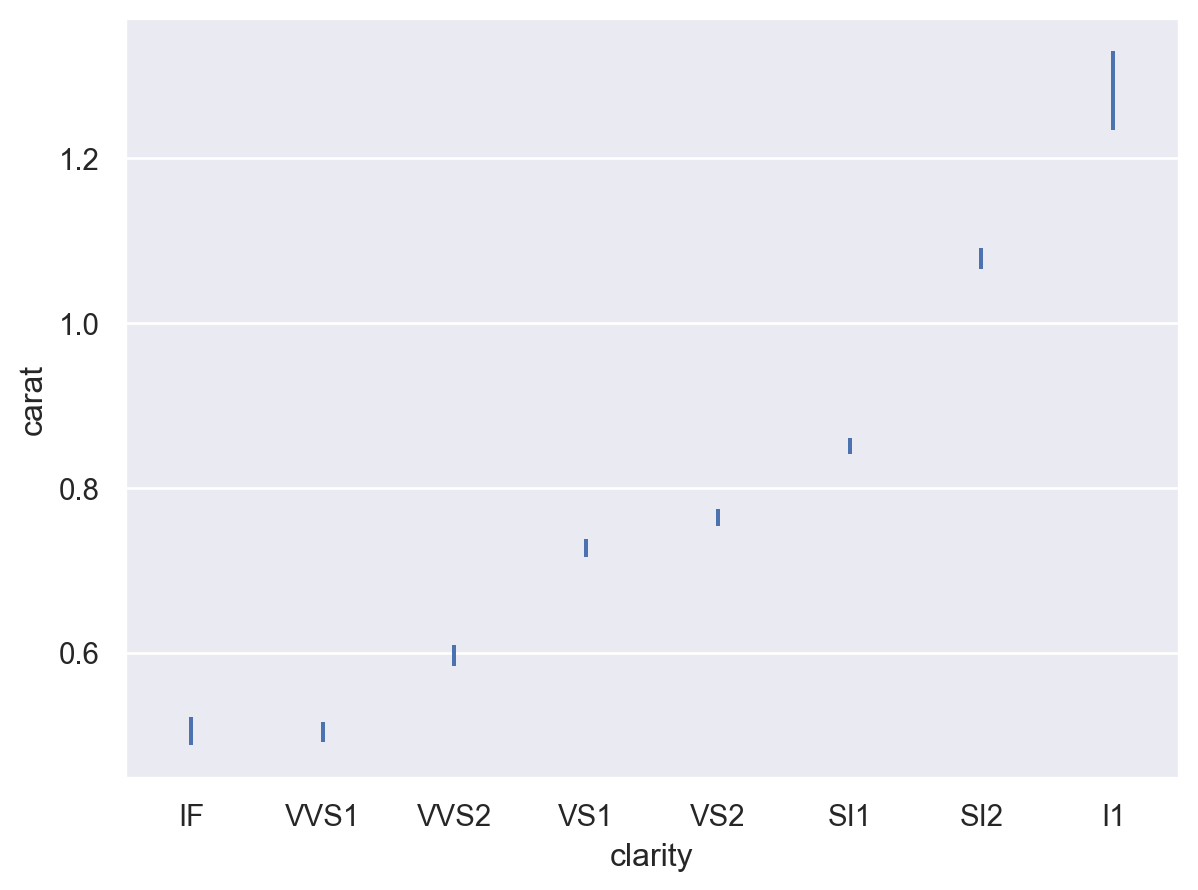
若要計算加權估計值 (和信賴區間),請在使用統計量的圖層中指定
weight變數p.add(so.Range(), so.Est(), weight="price")