seaborn.clustermap#
- seaborn.clustermap(data, *, pivot_kws=None, method='average', metric='euclidean', z_score=None, standard_scale=None, figsize=(10, 10), cbar_kws=None, row_cluster=True, col_cluster=True, row_linkage=None, col_linkage=None, row_colors=None, col_colors=None, mask=None, dendrogram_ratio=0.2, colors_ratio=0.03, cbar_pos=(0.02, 0.8, 0.05, 0.18), tree_kws=None, **kwargs)#
將矩陣數據集繪製為階層式群集熱圖。
此函數需要 scipy 才能使用。
- 參數:
- data2D 類陣列
用於群集的矩形數據。不能包含 NAs。
- pivot_kwsdict,可選
如果
data是一個整潔的資料框架,可以提供樞紐分析的關鍵字參數來建立矩形資料框架。- methodstr,可選
用於計算群集的連結方法。請參閱
scipy.cluster.hierarchy.linkage()文件以獲取更多資訊。- metricstr,可選
用於數據的距離度量。請參閱
scipy.spatial.distance.pdist()文件以獲取更多選項。若要對列和欄使用不同的度量(或方法),您可以自行建立每個連結矩陣,並將其作為{row,col}_linkage提供。- z_scoreint 或 None,可選
0 (列) 或 1 (欄)。是否計算列或欄的 z 分數。Z 分數為:z = (x - 平均值)/標準差,因此每一列(欄)的值都會減去該列(欄)的平均值,然後除以該列(欄)的標準差。這確保每列(欄)的平均值為 0,變異數為 1。
- standard_scaleint 或 None,可選
0 (列) 或 1 (欄)。是否將該維度標準化,這表示對於每一列或欄,都減去最小值,並將每個值除以其最大值。
- figsizetuple of (寬度, 高度),可選
圖表的整體大小。
- cbar_kwsdict,可選
要傳遞給
heatmap()中的cbar_kws的關鍵字參數,例如,在色彩條中新增標籤。- {row,col}_clusterbool,可選
如果為
True,則對 {列,欄} 進行群集。- {row,col}_linkage
numpy.ndarray,可選 列或欄的預先計算的連結矩陣。請參閱
scipy.cluster.hierarchy.linkage()以瞭解特定格式。- {row,col}_colors類列表或 pandas DataFrame/Series,可選
用於標示列或欄的顏色列表。有助於評估群組中的樣本是否群集在一起。可以使用巢狀列表或 DataFrame 來進行多個顏色層級的標示。如果給定為
pandas.DataFrame或pandas.Series,顏色的標籤會從 DataFrame 的欄名稱或 Series 的名稱中提取。DataFrame/Series 的顏色也會根據其索引與資料進行比對,以確保以正確的順序繪製顏色。- maskbool 陣列或 DataFrame,可選
如果傳遞此參數,則當
mask為 True 時,將不會顯示資料格。具有遺失值的資料格會自動被遮罩。僅用於視覺化,不適用於計算。- {dendrogram,colors}_ratiofloat 或一對 float,可選
分配給兩個邊緣元素的圖表大小比例。如果給定一對值,則它們對應於 (列、欄) 比例。
- cbar_postuple of (左, 下, 寬度, 高度),可選
圖表中色彩條軸的位置。設定為
None會停用色彩條。- tree_kwsdict,可選
用於繪製樹狀圖的線條的
matplotlib.collections.LineCollection的參數。- kwargs其他關鍵字參數
所有其他關鍵字參數都會傳遞至
heatmap()。
- 傳回值:
ClusterGrid一個
ClusterGrid實例。
另請參閱
heatmap將矩形資料繪製為顏色編碼的矩陣。
注意事項
返回的物件有一個
savefig方法,如果您想在不裁剪樹狀圖的情況下儲存圖形物件,應該使用此方法。要存取重新排序的列索引,請使用:
clustergrid.dendrogram_row.reordered_ind欄索引,請使用:
clustergrid.dendrogram_col.reordered_ind範例
繪製具有行列分群的熱圖
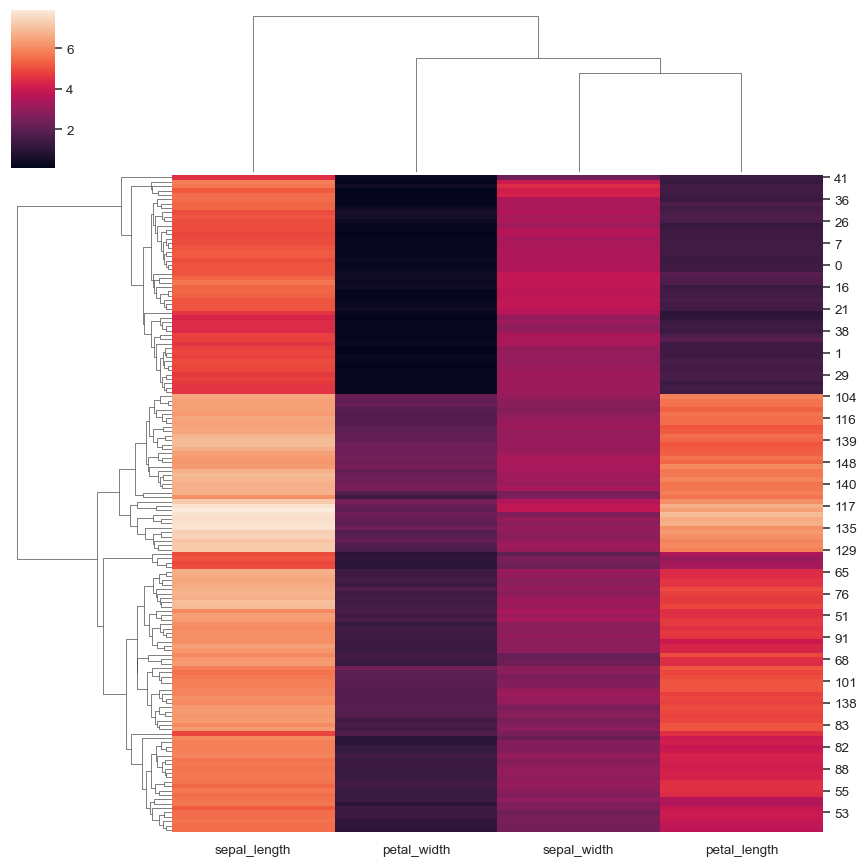
iris = sns.load_dataset("iris") species = iris.pop("species") sns.clustermap(iris)
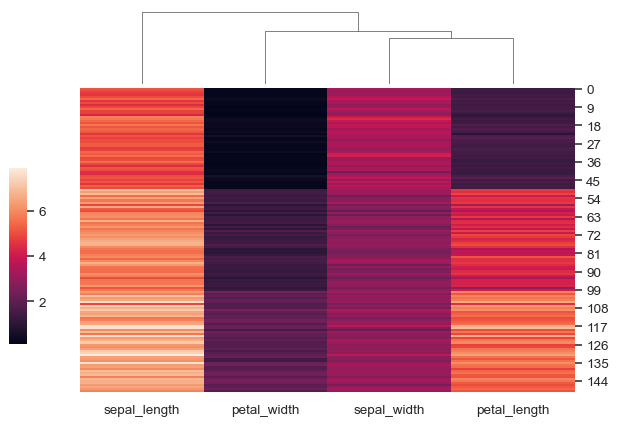
變更圖形的大小和佈局
sns.clustermap( iris, figsize=(7, 5), row_cluster=False, dendrogram_ratio=(.1, .2), cbar_pos=(0, .2, .03, .4) )
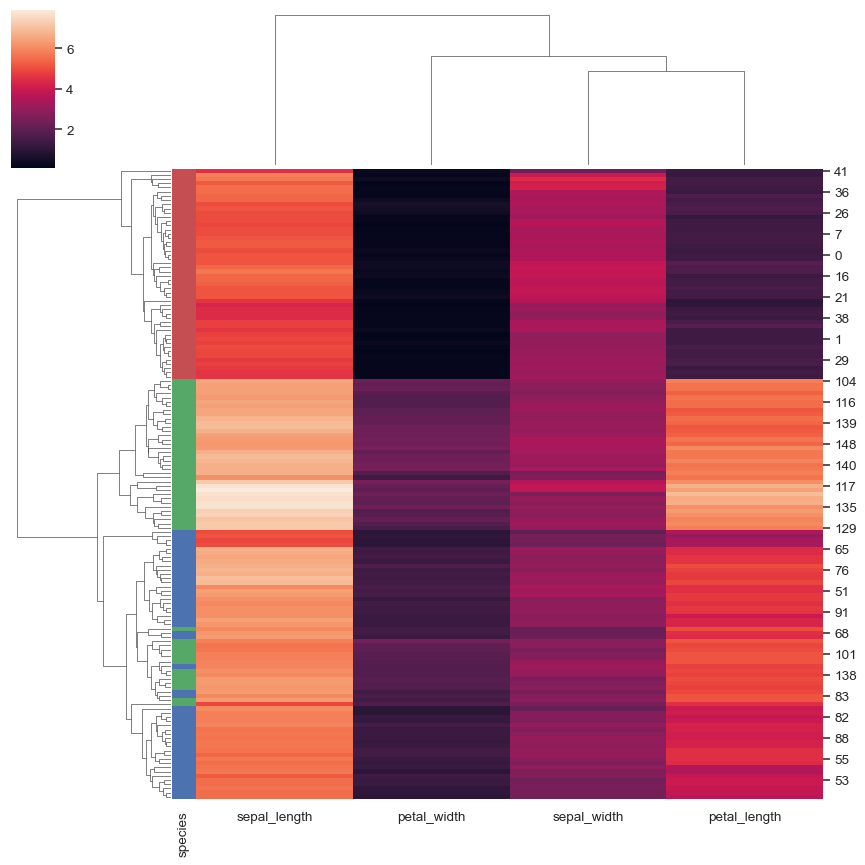
新增彩色標籤以識別觀測值
lut = dict(zip(species.unique(), "rbg")) row_colors = species.map(lut) sns.clustermap(iris, row_colors=row_colors)
使用不同的顏色映射並調整顏色範圍的限制
sns.clustermap(iris, cmap="mako", vmin=0, vmax=10)
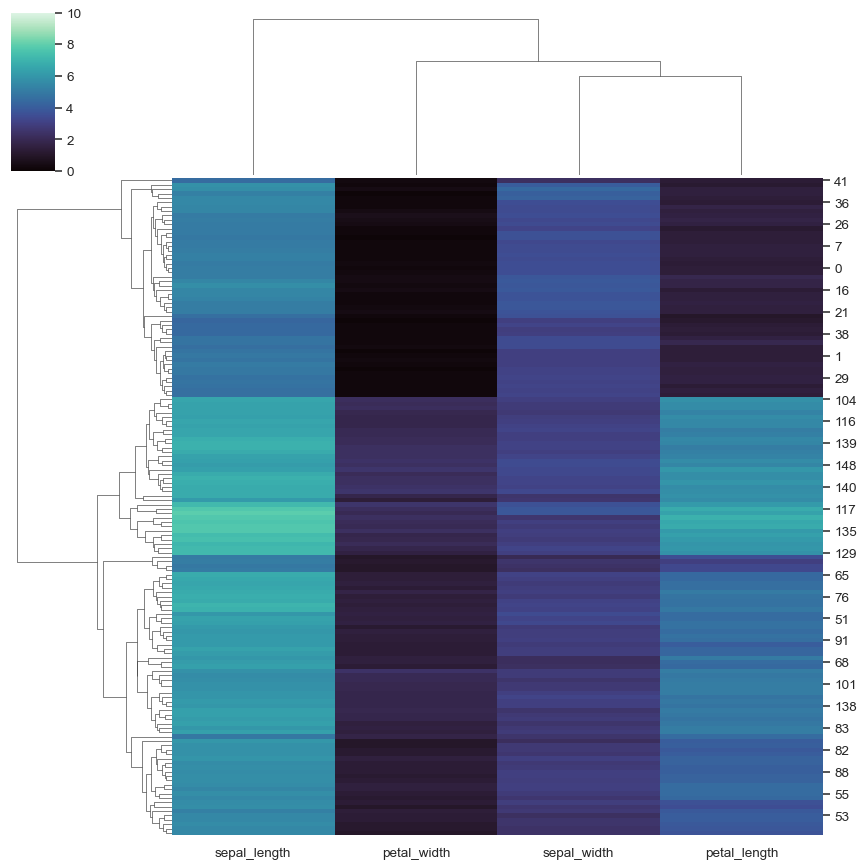
使用不同的分群參數
sns.clustermap(iris, metric="correlation", method="single")
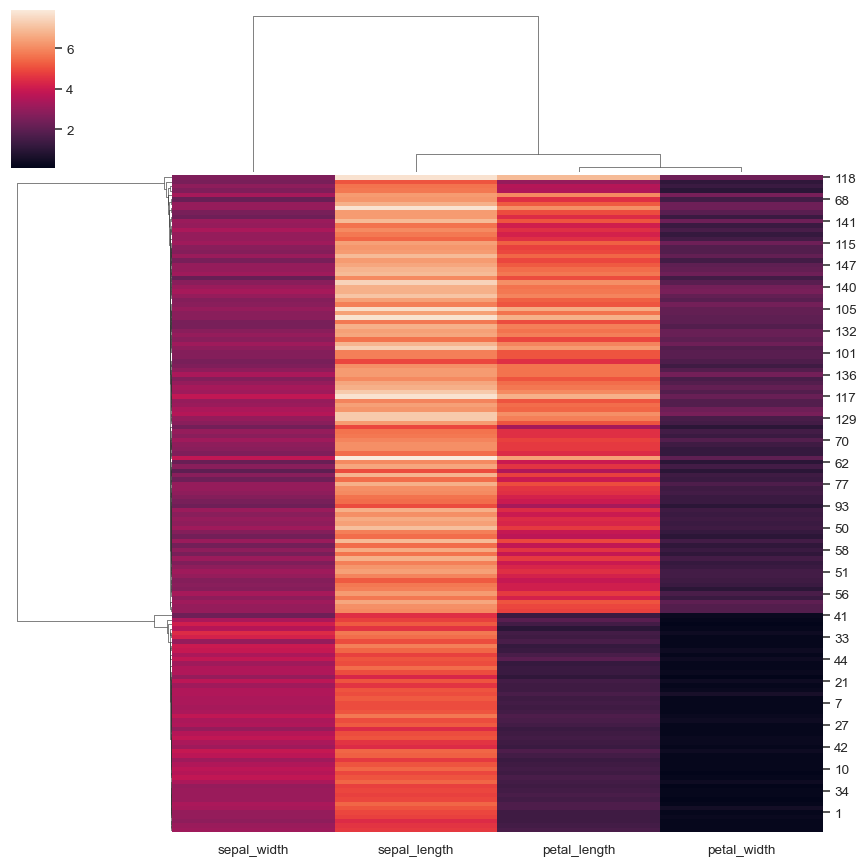
標準化欄位內的數據
sns.clustermap(iris, standard_scale=1)
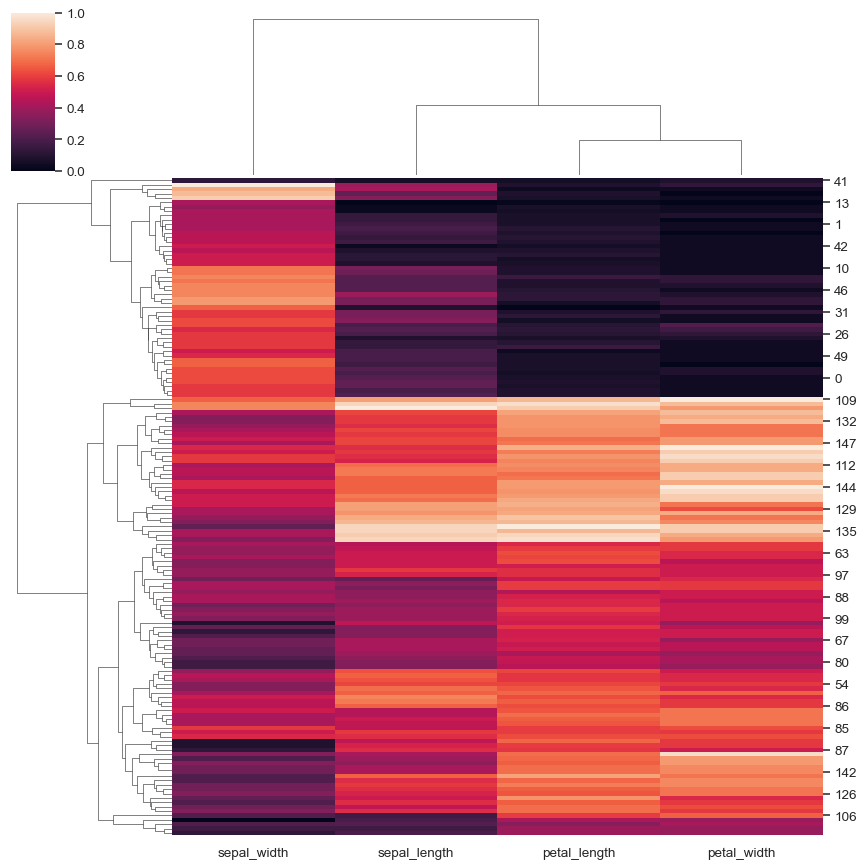
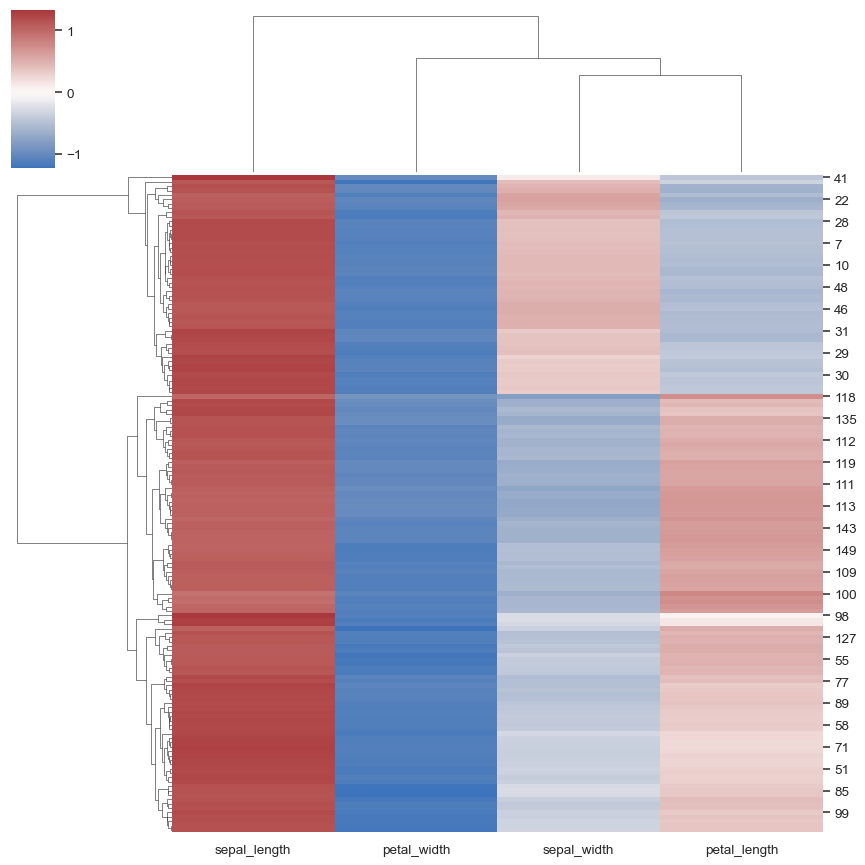
正規化列內的數據
sns.clustermap(iris, z_score=0, cmap="vlag", center=0)