估計回歸擬合#
許多資料集包含多個量化變數,而分析的目標通常是將這些變數相互關聯。我們先前已探討能藉由顯示兩個變數的聯合分佈來達成此目的的函式。然而,使用統計模型來估計兩個雜訊觀測集之間的簡單關係會很有幫助。本章討論的函式將透過線性回歸的常見架構來執行此操作。
本著 Tukey 的精神,seaborn 中的回歸繪製圖主要用於新增視覺指南,幫助在探索性資料分析中強調資料集的模式。換句話說,seaborn 本身不是一個用於統計分析的套件。若要取得與回歸模型的擬合相關的量化測量,您應使用statsmodels。然而,seaborn 的目標是讓使用者透過視覺化快速且輕鬆地探索資料集,因為這樣做與透過統計表探索資料集同樣重要(如果不是更重要的話)。
繪製線性回歸模型的函式#
可使用來視覺化線性擬合的兩個函式為regplot()和lmplot()。
在最簡單的呼叫中,兩個函數都會繪製兩個變數的散佈圖,x 與 y,然後擬合回歸模型 y ~ x,並繪製回歸線和回歸的 95% 信賴區間
tips = sns.load_dataset("tips")
sns.regplot(x="total_bill", y="tip", data=tips);
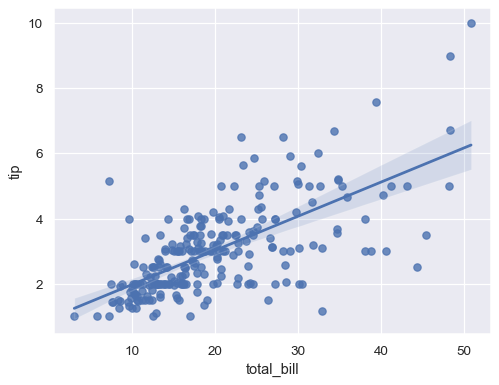
sns.lmplot(x="total_bill", y="tip", data=tips);
這些函數會繪製類似的圖形,但是 regplot() 是一個 軸級別函數,而 lmplot() 是一個圖形級別函數。此外,regplot() 接受 x 和 y 變數,格式多元,包括簡單的 numpy 陣列、pandas.Series 物件或做為 pandas.DataFrame 物件中變數的參考,並傳遞給 data。相對地,lmplot() 的 data 為必要參數,而 x 和 y 變數必須指定為字串。最後,只有 lmplot() 有 hue 為參數。
不過,核心的功能性是類似的,所以本教學會專注在 lmplot():.
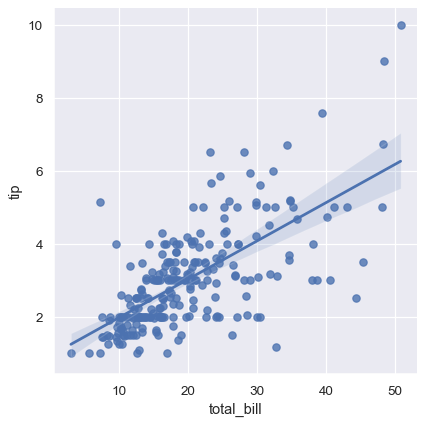
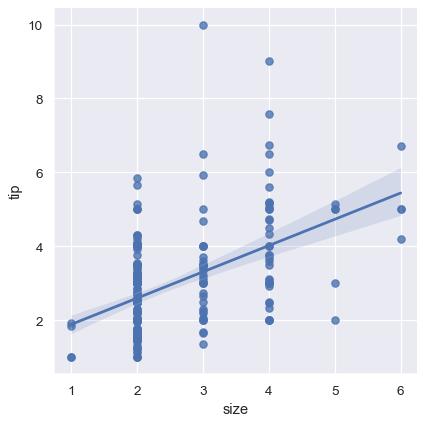
當其中一個變數採取離散值時,可以擬合線性回歸,然而,這種資料集所產生的簡單散佈圖通常不是最佳的
sns.lmplot(x="size", y="tip", data=tips);
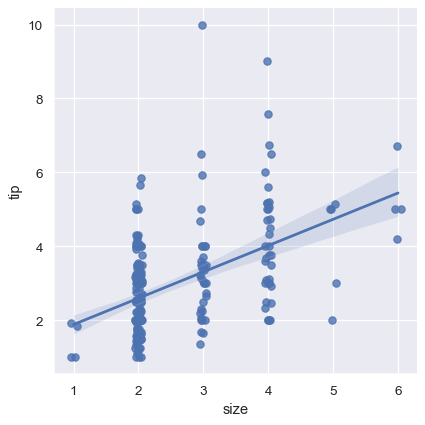
一個選項是針對離散值加入一些隨機雜訊(「抖動」),以使得這些值的分配更加明確。請注意,抖動僅套用在散佈圖資料中,並不會影響回歸線本身的擬合
sns.lmplot(x="size", y="tip", data=tips, x_jitter=.05);
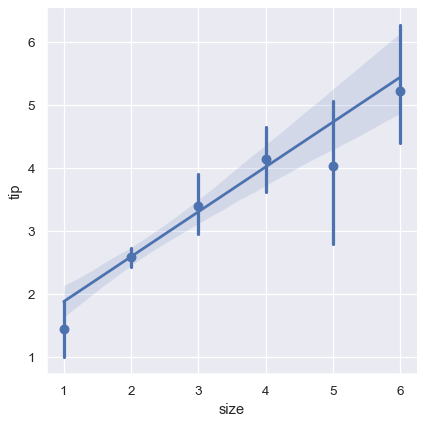
另一個選項是對每一個區間中的觀測值求和,以繪製出中心趨勢的估計值和信心區間
sns.lmplot(x="size", y="tip", data=tips, x_estimator=np.mean);
建立不同類型的函數模型#
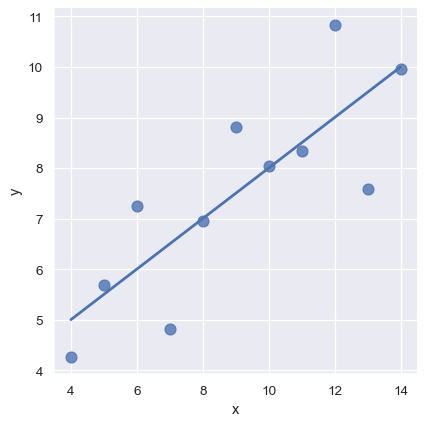
上述使用到的簡單線性回歸函數模型非常容易擬和,但是並不適用於某些類型的資料集。 Anscombe 樣本 是一個範例,展示出簡單線性回歸如何提供一個關係估計值,而簡單的視覺檢查卻可以清楚地看到兩者之間有差異。例如,在第一個案例中,線性回歸是一個好的函數模型
anscombe = sns.load_dataset("anscombe")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
ci=None, scatter_kws={"s": 80});
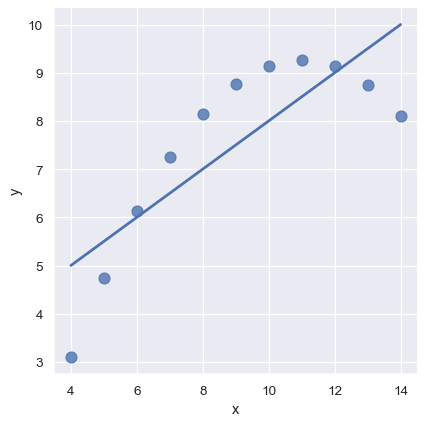
第二個資料集中的線性關係是一樣的,但是繪製出的圖表清楚地顯示這並不是一個好的函數模型
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
ci=None, scatter_kws={"s": 80});
如果有這種高階關係,則可以擬和 lmplot() 和 regplot() 多項式回歸函數模型,以探索資料集中非線性趨勢的簡單類型
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
order=2, ci=None, scatter_kws={"s": 80});
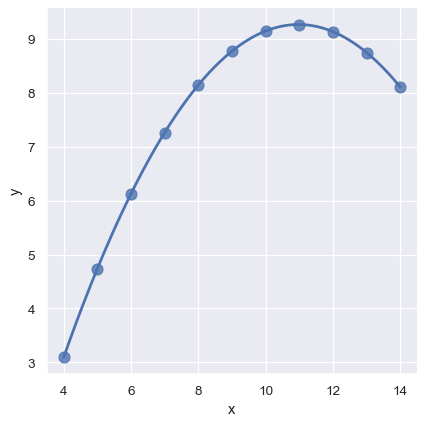
「異常值」觀測值會因為研究主題關聯性之外的某種原因而出現偏差,這會帶來另一個問題
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
ci=None, scatter_kws={"s": 80});
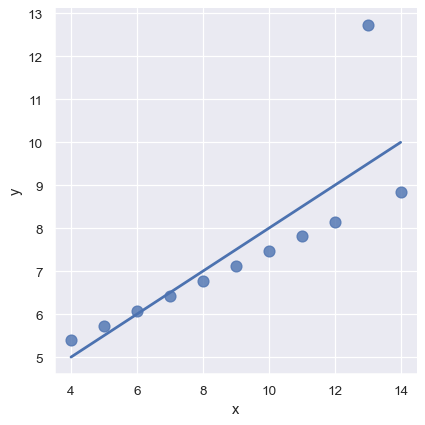
如果有異常值,擬和一個穩健回歸會很有用,它會使用一個不同的損失函數來降低相對較大的殘差權重
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),
robust=True, ci=None, scatter_kws={"s": 80});
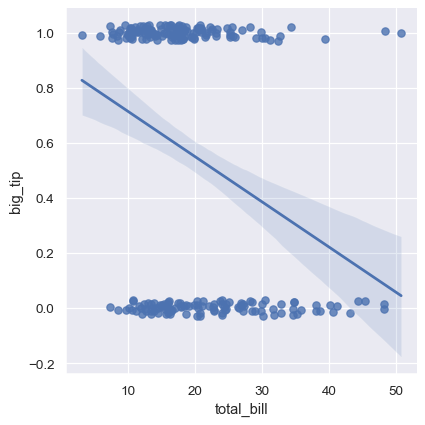
當 y 變數為二元時,簡單線性回歸也會「起作用」,但會提供不可信的預測
tips["big_tip"] = (tips.tip / tips.total_bill) > .15
sns.lmplot(x="total_bill", y="big_tip", data=tips,
y_jitter=.03);
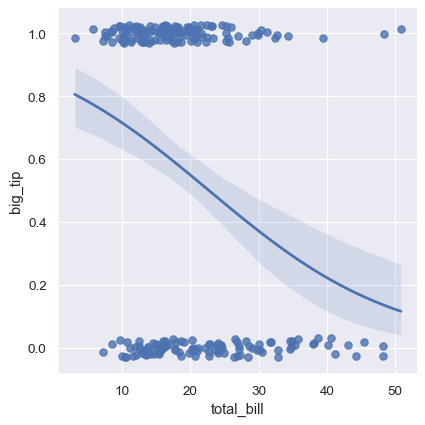
在這種情況下的解決方案是擬合一個邏輯回歸,使得回歸線顯示在給定的 x 值下,y = 1 的預測機率
sns.lmplot(x="total_bill", y="big_tip", data=tips,
logistic=True, y_jitter=.03);
請注意,邏輯回歸估計值在運算上需要密集許多(對於穩健回歸來說也是如此)。由於回歸線周圍的信心區間是使用 bootstrapping 程序計算出來的,您可能希望關閉它以進行更快的反覆運算 (使用 ci=None)
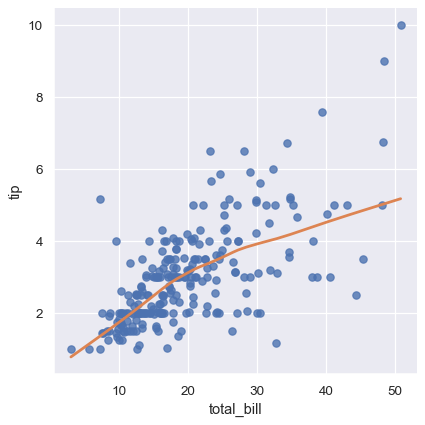
另一種完全不同的方法是使用 低域平滑 來擬合非參數回歸。這種方法有最少的假設,儘管在運算上需要密集計算,因此目前根本不計算信心區間
sns.lmplot(x="total_bill", y="tip", data=tips,
lowess=True, line_kws={"color": "C1"});
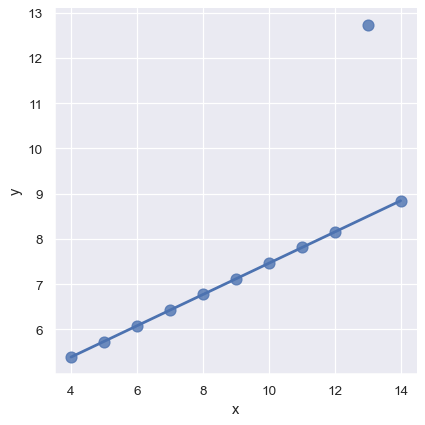
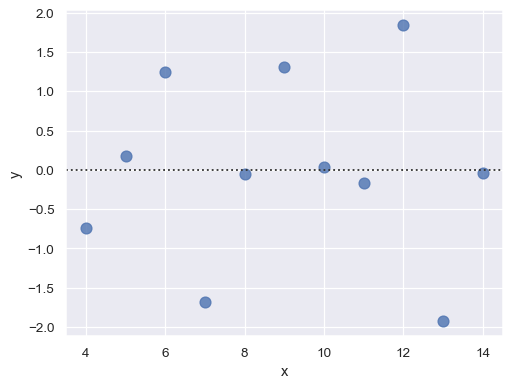
函式 residplot() 可作為檢查簡單迴歸模型是否適用於特定資料集的實用工具。它會套用並移除簡單線性迴歸,然後繪製每項觀測的殘差值。理想情況下,這些數值應隨機散佈在 y = 0
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),
scatter_kws={"s": 80});
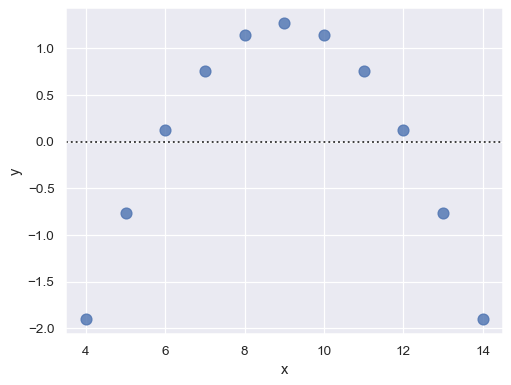
如果殘差中存在結構,表示簡單線性迴歸並不適用
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),
scatter_kws={"s": 80});
根據其他變數調整#
上方繪圖展示了透過多種方式探索變數對之間關係的方法。不過,「這些變數之間的關係隨著第三個變數的不同而如何改變?」通常會是一個更有趣的問題。這是 regplot() 和 lmplot() 之間主要差異之處。regplot() 永遠只呈現一種關係,lmplot() 則將 regplot() 與 FacetGrid 結合使用,以繪製多種透過 hue 映射或分面顯示的擬合值。
分離關係的最佳方法是在同一軸線上繪製兩層,並利用色彩將其區分
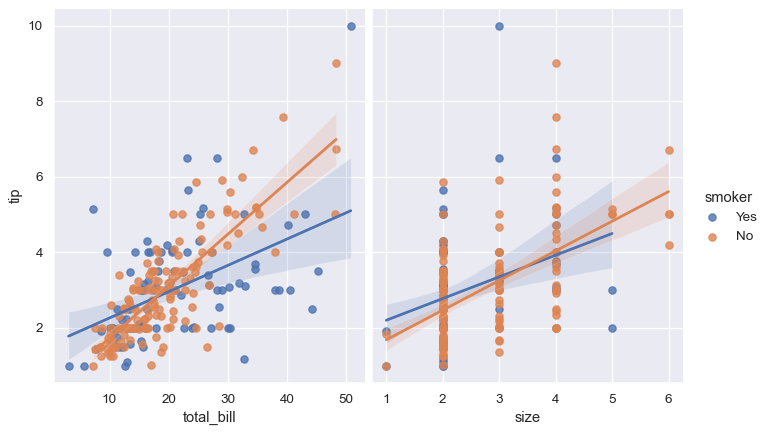
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips);
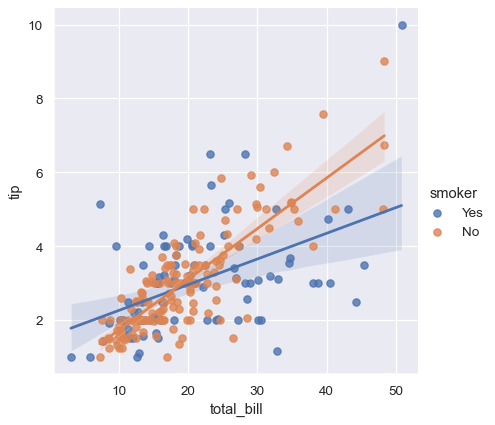
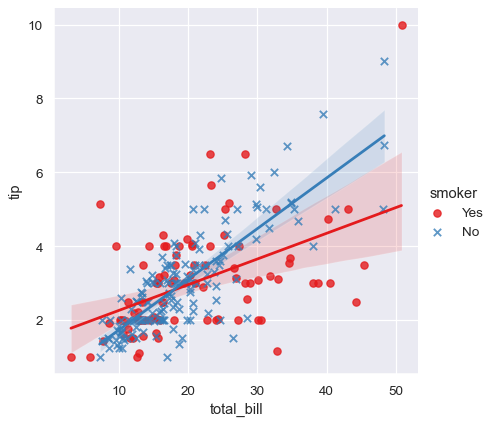
與 relplot() 不同,無法將不同的變數映射到散佈圖的樣式屬性,但您可將 hue 變數與標記形狀重複編碼
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips,
markers=["o", "x"], palette="Set1");
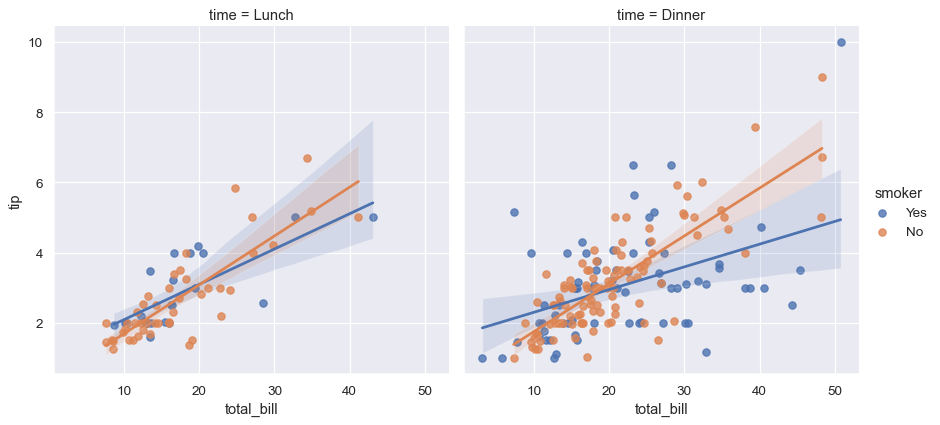
如要新增其他變數,您可以在網格的列或欄中繪製多個「分面」,其中各層的變數即會顯示在分面中
sns.lmplot(x="total_bill", y="tip", hue="smoker", col="time", data=tips);
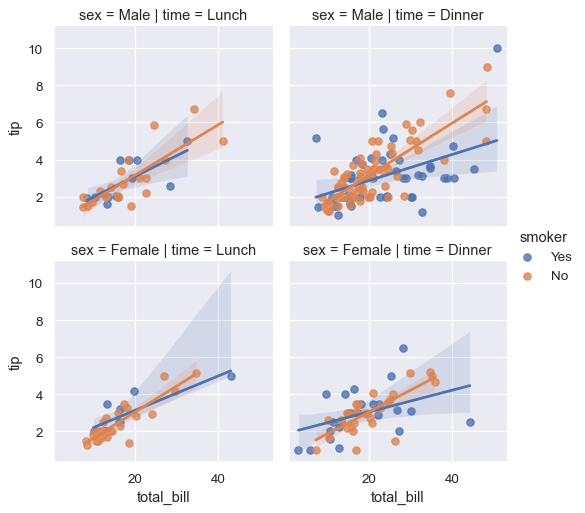
sns.lmplot(x="total_bill", y="tip", hue="smoker",
col="time", row="sex", data=tips, height=3);
在其他背景下繪製迴歸#
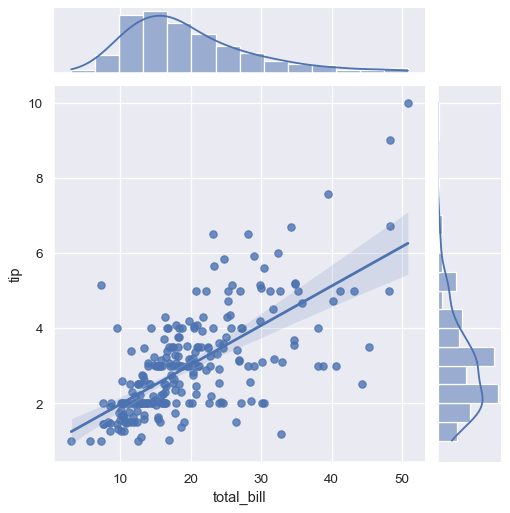
其他幾個 seaborn 函數會在較大型、較複雜的繪圖脈絡中使用 regplot()。第一個是我們在 分布教學 中介紹的 jointplot() 函數。除了前面討論過的繪圖樣式,jointplot() 還可以使用 regplot() 對聯合座標軸顯示線性回歸擬合,傳遞 kind="reg"
sns.jointplot(x="total_bill", y="tip", data=tips, kind="reg");
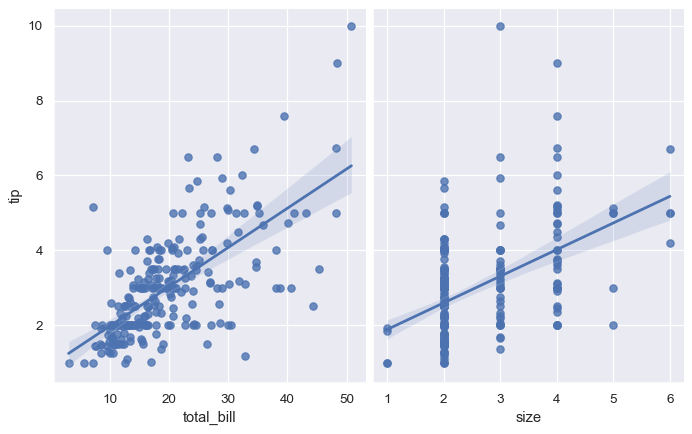
使用 kind="reg" 和 pairplot() 函數,結合 regplot() 和 PairGrid,來顯示資料集中變數之間的線性關係。特別注意這和 lmplot() 的不同。在以下圖形中,兩個座標軸不會顯示受制於第三個變數兩個層級的相同關係;PairGrid() 被用來顯示資料集中不同變數對之間的多重關係
sns.pairplot(tips, x_vars=["total_bill", "size"], y_vars=["tip"],
height=5, aspect=.8, kind="reg");
兩個函數都透過 hue 參數,內建了針對其他分類變數的約束
sns.pairplot(tips, x_vars=["total_bill", "size"], y_vars=["tip"],
hue="smoker", height=5, aspect=.8, kind="reg");